
SEO Spiders: Waarom Ze Belangrijk Zijn voor Je Site
Spiders zijn bots die worden ingezet voor spamdoeleinden en kunnen grote problemen veroorzaken voor je bedrijf. Lees meer over ze in het artikel.
4 min lezen
SEO
DigitalMarketing
+3
Ontdek waarom webcrawlers ‘spiders’ worden genoemd, hoe ze werken en hun cruciale rol in zoekmachine-indexering. Leer de technische mechanismen achter webcrawling in 2025 kennen.
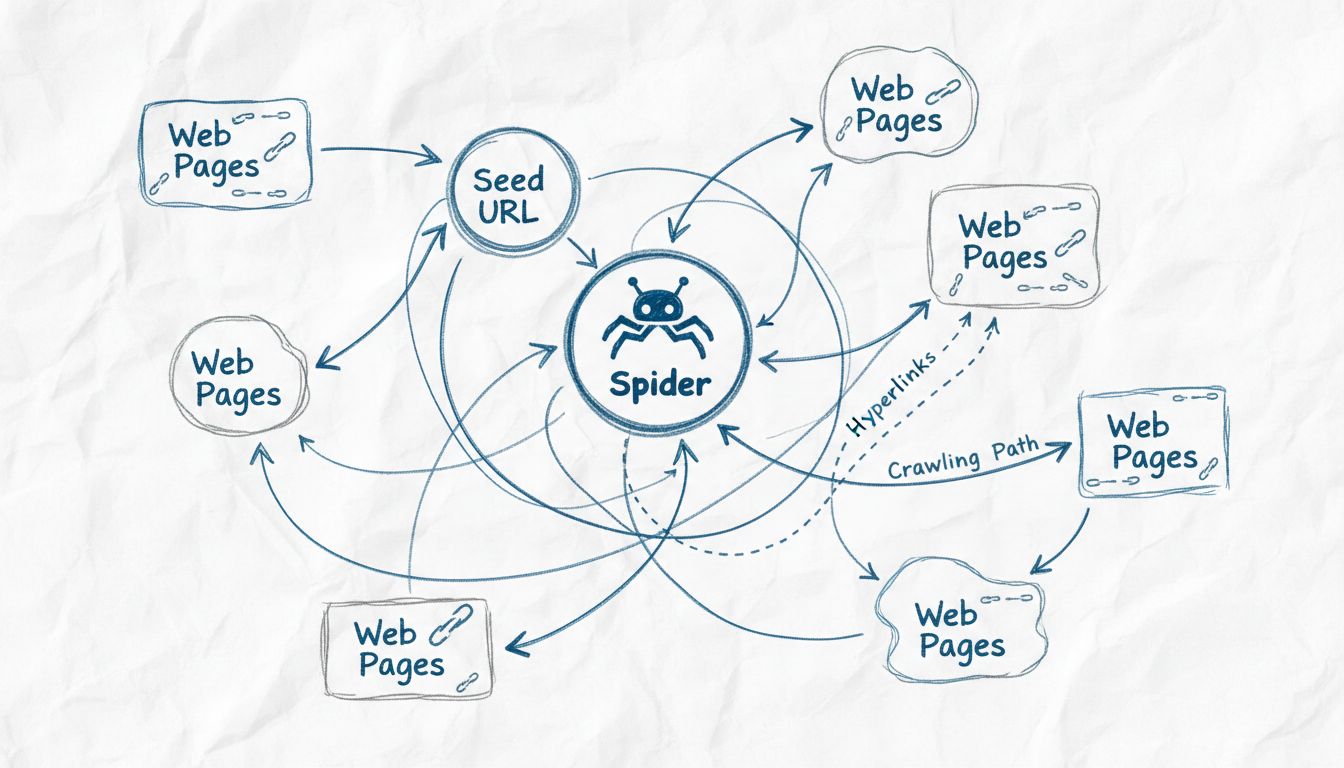
Webcrawlers worden 'spiders' genoemd omdat ze systematisch het web doorzoeken door links van de ene naar de andere pagina te volgen, vergelijkbaar met hoe een spin haar web doorkruist. De term 'spider' is een treffende metafoor voor deze geautomatiseerde bots die het onderling verbonden netwerk van websites doorkruisen om webinhoud te ontdekken, indexeren en organiseren voor zoekmachines.
De term “spider” voor webcrawlers is ontstaan uit een slimme metaforische vergelijking tussen hoe deze geautomatiseerde bots het internet verkennen en hoe echte spinnen hun web doorkruisen. Net zoals een spin een ingewikkeld web weeft om informatie over haar omgeving te verzamelen en te organiseren, doorkruisen webcrawlers het onderling verbonden netwerk van hyperlinks op het wereldwijde web om digitale inhoud te ontdekken, analyseren en organiseren. De metafoor is bijzonder passend omdat beide entiteiten systematisch te werk gaan via complexe netwerken, waarbij ze paden volgen om nieuwe bestemmingen te bereiken en informatie te verzamelen. Deze naamgeving is zo ingeburgerd geraakt in de technologie dat de termen “spider”, “crawler” en “bot” tegenwoordig door elkaar worden gebruikt wanneer men spreekt over webindexeringstechnologie. De visuele en conceptuele gelijkenis tussen een spinnenweb en de structuur van het internet maakt deze terminologie zowel intuïtief als memorabel voor zowel technische professionals als algemene gebruikers.
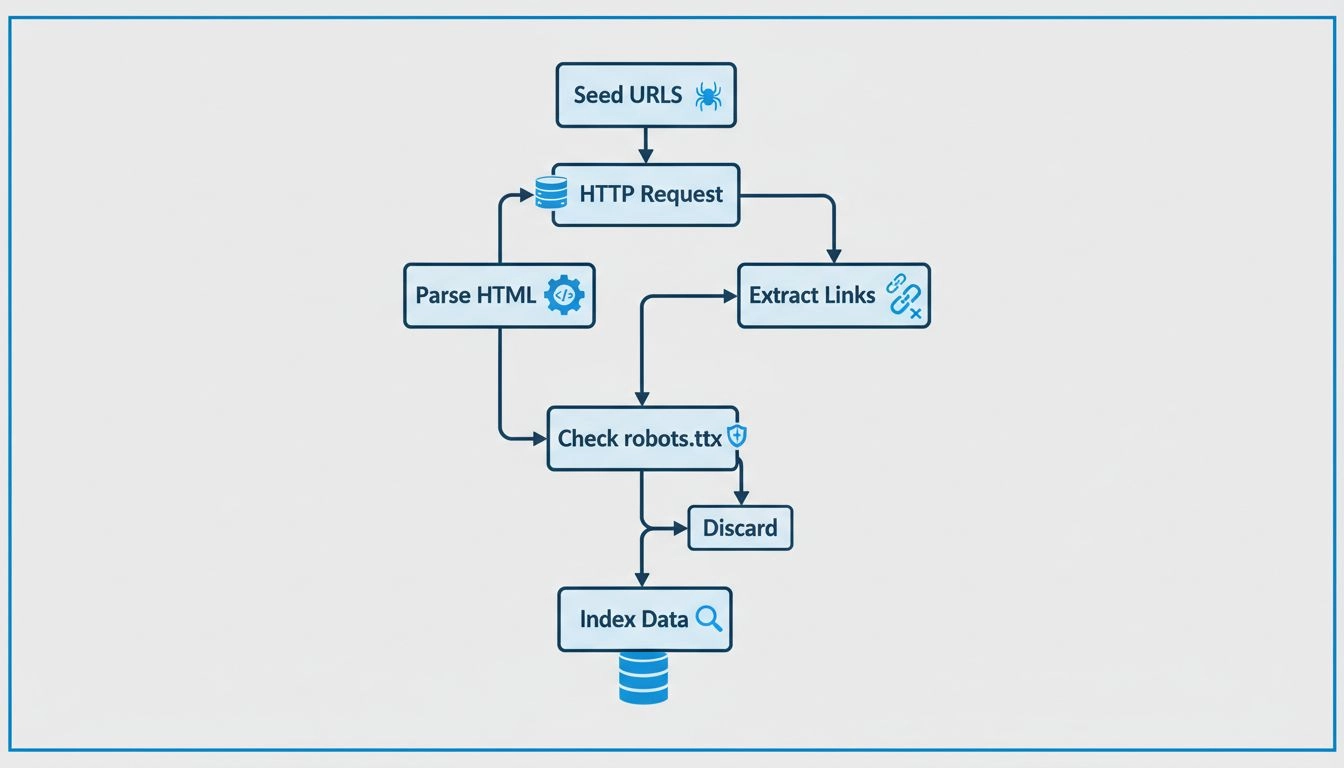
Webspiders werken volgens een verfijnd maar systematisch proces dat begint met een enkel startpunt, de zogenaamde “seed URL”. Vanaf deze startlocatie analyseert de spider de HTML-code van de webpagina en haalt alle hyperlinks op die op die pagina aanwezig zijn. Vervolgens volgt de spider deze links naar nieuwe pagina’s, waarbij het proces continu wordt herhaald om het bereik over het web uit te breiden. Deze methodische aanpak stelt spiders in staat om miljoenen onderling verbonden pagina’s te ontdekken zonder handmatige aanwijzingen of menselijke tussenkomst. De spider houdt een zogenaamde “crawl frontier” bij, wat in feite een wachtrij is van URL’s die zijn ontdekt maar nog niet bezocht. Op basis van specifieke crawlbeleid en algoritmen bepaalt de spider welke URL’s als volgende worden bezocht, waarbij factoren als pagina-belang, updatefrequentie en relevantie voor de indexeringsdoelen van de zoekmachine worden meegenomen.
Stel geavanceerde tracking in binnen enkele minuten. Geen creditcard vereist.
Moderne webspiders zijn gebouwd op een geavanceerde technische architectuur die hen in staat stelt enorme hoeveelheden data efficiënt te verwerken. De kerncomponenten van een webcrawler zijn onder andere het URL-frontiermanagementsysteem, dat URL’s voor crawling organiseert en prioriteert; het ophaalmechanisme dat pagina-inhoud met hoge snelheid downloadt; de parseermotor die links en metadata uit HTML haalt; en het indexeringssysteem dat verwerkte informatie opslaat voor zoekopdrachten. Webspiders moeten ook beleefdheidsregels implementeren om te voorkomen dat doelservers worden overbelast met te veel verzoeken, herbezoekbeleid om te bepalen hoe vaak pagina’s opnieuw gecrawld moeten worden voor updates, en selectiebeleid om te bepalen welke links het meest waardevol zijn om te volgen. Moderne spiders zijn geëvolueerd om JavaScript- en AJAX-inhoud te kunnen verwerken, hoewel ze nog steeds prioriteit geven aan standaard HTML voor betrouwbare inhoudsontdekking. Door de gedistribueerde aard van moderne crawlers kunnen grootschalige spiders op meerdere servers tegelijk werken, waardoor ze verschillende websites parallel kunnen crawlen en hun algehele efficiëntie en dekking sterk vergroten.
Hoewel de termen “spider” en “crawler” vaak door elkaar worden gebruikt, is het belangrijk te begrijpen dat ze dezelfde technologie aanduiden met verschillende naamgevingen. Webspiders verschillen echter aanzienlijk van webscrapers, die soms worden verward met crawlers. Het belangrijkste verschil zit in hun doel en reikwijdte: webcrawlers richten zich op algemene informatieverzameling over websites en hun structuur, en volgen breed links over het web om uitgebreide indexen op te bouwen. Webspiders, specifiek gebruikt door zoekmachines, concentreren zich op het indexeren van tekstuele inhoud zodat deze doorzoekbaar en vindbaar wordt. Webscrapers daarentegen zijn precisietools die ontworpen zijn om specifieke gegevens uit websites te halen, zoals productprijzen, contactinformatie of recensies. Scrapers richten zich meestal op bepaalde websites of gegevenstypes in plaats van breed te crawlen over het web. Bovendien respecteren crawlers en spiders meestal robots.txt-bestanden en de gebruiksvoorwaarden van websites, terwijl scrapers daar soms geen rekening mee houden. Het begrijpen van deze verschillen is essentieel voor website-eigenaren en ontwikkelaars die willen bepalen hoe hun inhoud wordt benaderd en geïndexeerd door geautomatiseerde systemen.
Wees de eerste die op de hoogte is van nieuwe functies en productupdates.
Webspiders zijn absoluut fundamenteel voor de werking van zoekmachines en de waarde die zij wereldwijd aan gebruikers bieden. Zonder spiders die continu webinhoud crawlen en indexeren, zouden zoekmachines niet weten welke websites er bestaan, welke inhoud ze bevatten of hoe relevant die inhoud is voor zoekopdrachten van gebruikers. Wanneer een spider een webpagina crawlt, beoordeelt deze tal van factoren zoals de paginastuctuur, relevantie van inhoud, gebruik van zoekwoorden en signalen over gebruikerservaring. Deze informatie wordt vervolgens opgeslagen in enorme indexen die zoekmachines gebruiken om gebruikersvragen te koppelen aan de meest relevante resultaten. De kwaliteit en frequentie van spider crawling beïnvloeden direct hoe snel nieuwe inhoud in de zoekresultaten verschijnt en hoe nauwkeurig zoekmachines pagina’s kunnen rangschikken. Zoekmachines zoals Google, Bing, Baidu en Yahoo onderhouden elk hun eigen, unieke spiderbots—Googlebot, Bingbot, Baiduspider en Slurp—elk met hun eigen algoritmen en crawlstrategieën, geoptimaliseerd voor de specifieke doelen en gebruikers van hun zoekmachine.
| Spider Bot | Zoekmachine | Primaire functie | Crawlstrategie | Belangrijkste kenmerken |
|---|---|---|---|---|
| Googlebot | Webpagina’s indexeren voor Google Search | Gedistribueerd crawlen met mobiele en desktopvarianten | Verwerkt JavaScript, geeft prioriteit aan mobile-first indexering, respecteert crawlbudget | |
| Bingbot | Microsoft Bing | Webpagina’s indexeren voor Bing Search | Parallel crawlen over meerdere servers | Efficiënt bandbreedtegebruik, respecteert robots.txt, ondersteunt meerdere contenttypes |
| Baiduspider | Baidu | Webpagina’s indexeren voor Baidu Search | Geoptimaliseerd voor Chinese taalinformatie | Gespecialiseerd voor Aziatische webinhoud, verwerkt vereenvoudigd en traditioneel Chinees |
| DuckDuckBot | DuckDuckGo | Webpagina’s indexeren voor privacygerichte zoekmachine | Beleefd crawlen met focus op privacy | Minimale gegevensverzameling, respecteert gebruikersprivacyvoorkeuren |
| YandexBot | Yandex | Webpagina’s indexeren voor Yandex Search | Gedistribueerd crawlen met regionale optimalisatie | Geoptimaliseerd voor Russische en Oost-Europese inhoud |
Website-eigenaren hebben verschillende tools en strategieën om te optimaliseren hoe spiders hun inhoud crawlen en indexeren. Het maken van een uitgebreide sitemap.xml-bestand biedt spiders een duidelijk overzicht van alle pagina’s die geïndexeerd moeten worden, wat de efficiëntie van crawling sterk verbetert en ervoor zorgt dat geen belangrijke pagina’s worden gemist. Het optimaliseren van metatags, waaronder title tags en meta descriptions, helpt spiders de inhoud van pagina’s te begrijpen en verbetert de weergave in zoekresultaten. Door een goed gestructureerd robots.txt-bestand in te stellen kunnen website-eigenaren spiders leiden naar belangrijke inhoud en ze weghouden van pagina’s die niet geïndexeerd moeten worden, zoals adminpanelen of dubbele inhoud. Regelmatig nieuwe en bijgewerkte inhoud toevoegen stimuleert spiders om websites vaker te bezoeken, waardoor indexen actueel blijven en de zichtbaarheid in zoekmachines wordt verbeterd. Website-eigenaren moeten er ook voor zorgen dat hun site-architectuur overzichtelijk en logisch is, met een duidelijke hiërarchische navigatie die het voor spiders makkelijk maakt om alle pagina’s te ontdekken. Het verbeteren van de laadsnelheid van pagina’s is cruciaal omdat spiders een beperkt crawlbudget hebben—de hoeveelheid middelen die zoekmachines toewijzen aan het crawlen van een specifieke site—en snellere pagina’s maken het mogelijk dat spiders meer inhoud binnen dat budget crawlen.
Ondanks hun verfijning staan webspiders voor tal van technische uitdagingen die hun effectiviteit kunnen beperken. Dynamische inhoud die wordt gegenereerd door JavaScript vormt een belangrijke belemmering, omdat niet alle spiders JavaScript kunnen uitvoeren om pagina’s te renderen zoals gebruikers ze zien. Door websites opgelegde snelheidslimieten beperken hoeveel verzoeken spiders binnen een bepaalde tijd kunnen doen, waardoor het mogelijk niet lukt grote websites volledig te indexeren. CAPTCHA-uitdagingen en andere anti-botmaatregelen kunnen spiders de toegang tot inhoud blokkeren, hoewel legitieme zoekmachinespiders meestal worden vrijgesteld. Dubbele inhoud over meerdere URL’s maakt het voor spiders onduidelijk welke versie geïndexeerd en gerangschikt moet worden, wat de zichtbaarheid in zoekresultaten kan verminderen. Crawler traps—opzettelijke of onbedoelde oneindige lussen in de website-structuur—kunnen spiderresources verspillen en crawlbudget verbruiken zonder productieve indexering. Bovendien betekent de exponentiële groei van webinhoud dat spiders onmogelijk alles kunnen crawlen en indexeren, waardoor geavanceerde algoritmen vereist zijn om te bepalen welke inhoud het belangrijkst is om te indexeren. Met wachtwoorden beveiligde pagina’s en geauthenticeerde inhoud blijven grotendeels ontoegankelijk voor publieke spiders, waardoor indexering van privé- of ledeninhoud beperkt blijft.
Webspidertechnologie blijft zich snel ontwikkelen naarmate het internet groeit en complexer wordt. Moderne spiders zijn steeds beter in staat geavanceerde webtechnologieën te verwerken, waaronder single-page applicaties, progressive web apps en dynamische contentrendering. Kunstmatige intelligentie en machine learning worden geïntegreerd in spideralgoritmen om context, gebruikersintentie en paginakwaliteit beter te begrijpen. De opkomst van generatieve AI stelt nieuwe eisen aan webcrawling, omdat AI-systemen voortdurend bijgewerkte, relevante en nauwkeurige informatie nodig hebben om effectief te functioneren. Enterprise webcrawlers zijn steeds geavanceerder geworden, waardoor bedrijven hun eigen websites kunnen crawlen voor interne zoekfunctionaliteit, contentbeheer en prestatiemonitoring. De focus op crawlefficiëntie is toegenomen naarmate websites groter en complexer worden, met spiders die nu slimmere prioriteringsalgoritmen toepassen om de waarde van elke crawl te maximaliseren. Privacyoverwegingen beïnvloeden ook de ontwikkeling van spiders, met meer nadruk op het respecteren van gebruikersprivacy terwijl effectieve inhoudsontdekking en indexering mogelijk blijven. Vooruitkijkend zullen webspiders waarschijnlijk nog intelligenter en efficiënter worden, waarbij ze geavanceerde technologieën inzetten om hun weg te vinden in een steeds complexer digitaal landschap, terwijl ze websitebeleid en gebruikersprivacy respecteren.
Net zoals webspiders systematisch het hele web crawlen en indexeren, volgt en optimaliseert PostAffiliatePro elke affiliate-relatie in uw netwerk. Onze geavanceerde trackingtechnologie zorgt ervoor dat geen enkele commissie wordt gemist en geen enkele kans verloren gaat.
Spiders zijn bots die worden ingezet voor spamdoeleinden en kunnen grote problemen veroorzaken voor je bedrijf. Lees meer over ze in het artikel.
Leer hoe webcrawlers werken, van seed-URL's tot indexering. Begrijp het technische proces, de verschillende typen crawlers, robots.txt-regels en hoe crawlers SE...
Crawlers verzamelen data en informatie van het internet door websites te bezoeken en pagina's te lezen. Ontdek meer over hun werking.
Sluit u aan bij onze gemeenschap van tevreden klanten en bied uitstekende klantenservice met Post Affiliate Pro.
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.