
Crawlers en hun Rol in de Zoekmachineranking
Crawlers verzamelen data en informatie van het internet door websites te bezoeken en pagina's te lezen. Ontdek meer over hun werking.
6 min lezen
SEO
Crawlers
+4
Leer wat de Google Spider (Googlebot) is, hoe deze websites crawlt en indexeert, en waarom dit essentieel is voor SEO. Ontdek hoe je jouw site kunt optimaliseren voor betere crawling.
De Google Spider, formeel bekend als Googlebot, is een geautomatiseerd programma dat websites crawlt om inhoud te ontdekken, te indexeren en op te slaan in Google's database. Hij volgt links om nieuwe of bijgewerkte pagina's te vinden, die vervolgens worden verwerkt en toegevoegd aan Google's zoekindex, zodat de zoekmachine relevante resultaten aan gebruikers kan bieden.
De Google Spider, formeel bekend als Googlebot, is een geautomatiseerd softwareprogramma dat systematisch het internet afspeurt om webinhoud te ontdekken, analyseren en indexeren. Het is het primaire hulpmiddel dat Google gebruikt om websites te verkennen, informatie te verzamelen en zijn enorme zoekindex op te bouwen. Zonder Googlebot zou Google geen nieuwe pagina’s kunnen ontdekken, updates aan bestaande inhoud kunnen detecteren of relevante zoekresultaten kunnen bieden aan miljarden gebruikers wereldwijd. De spider werkt continu en bezoekt dagelijks miljoenen websites om ervoor te zorgen dat de index van Google actueel en compleet blijft.
Googlebot is in feite een geavanceerde webcrawler die een complex algoritmisch proces volgt om te bepalen welke sites bezocht worden, hoe vaak ze gecrawld worden en hoeveel pagina’s er van elk domein worden opgehaald. De crawler leest de HTML-code, tekstinhoud en metadata van elke bezochte pagina, waarna deze informatie wordt opgeslagen in Google’s centrale database. Dit indexeringsproces is fundamenteel voor het functioneren van zoekmachines en heeft direct invloed op de zichtbaarheid van je website in de zoekresultaten.
De Google Spider werkt volgens een goed gedefinieerd crawlproces dat begint met een basislijst van bekende webpagina’s. Deze initieel lijst wordt gegenereerd uit eerdere crawlprocessen en voortdurend aangevuld met sitemapgegevens die door webmasters via Google Search Console worden aangeleverd. Wanneer Googlebot een website bezoekt, leest hij niet alleen de inhoud—hij voert een uitgebreide analyse uit van de paginastructuur, volgt interne en externe links en identificeert eventuele wijzigingen of nieuwe content die sinds het laatste bezoek zijn toegevoegd.
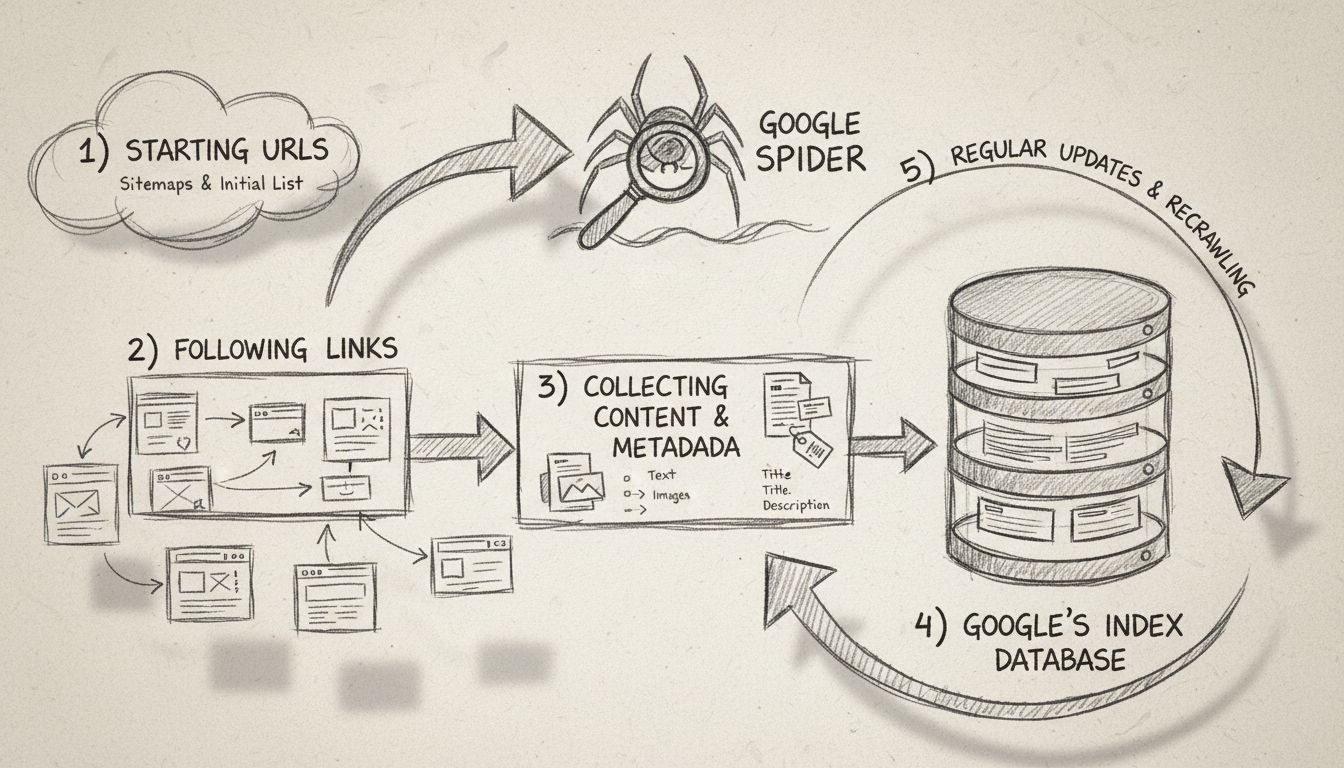
Het crawlproces volgt deze belangrijke stappen: Ten eerste begint Googlebot met een lijst van webpagina-URL’s uit eerdere crawls en sitemaps. Ten tweede navigeert hij door websites door links (zowel SRC- als HREF-attributen) op elke pagina te volgen om nieuwe content te ontdekken. Ten derde haalt de crawler de inhoud van elke pagina op en analyseert deze, inclusief tekst, HTML-structuur, metadata en andere relevante informatie. Ten vierde wordt deze verzamelde data naar Google’s servers gestuurd voor verwerking en opslag in de zoekindex. Tot slot bezoekt Googlebot websites op regelmatige basis opnieuw om te controleren op nieuwe inhoud, updates of wijzigingen aan bestaande pagina’s.
Stel geavanceerde tracking in binnen enkele minuten. Geen creditcard vereist.
Google gebruikt meerdere gespecialiseerde crawler-varianten, elk ontworpen voor specifieke doeleinden en te herkennen aan unieke user-agent strings. Het begrijpen van deze verschillende typen helpt website-eigenaren hun site te optimaliseren voor de juiste crawler. De belangrijkste Googlebot-varianten zijn de desktop-crawler, mobiele crawler, videocrawler, afbeeldingscrawler en nieuwscrawler, die elk een specifieke rol spelen binnen het indexeringsecosysteem van Google.
| Googlebot-type | User-Agent String | Doel |
|---|---|---|
| Googlebot (Desktop) | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) | Crawlt desktopversies van websites voor de algemene zoekindex |
| Googlebot (Mobile) | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) | Crawlt mobiel geoptimaliseerde versies van websites |
| Googlebot-Video | Googlebot-Video/1.0 | Indexeert videocontent die op webpagina’s is ingesloten |
| Googlebot-Image | Googlebot-Image/1.0 | Crawlt en indexeert afbeeldingen voor Google Afbeeldingen |
| Googlebot-News | Googlebot-News | Crawlt nieuwscontent voor Google Nieuws-aggregatie |
Naast deze primaire crawlers exploiteert Google ook gespecialiseerde bots voor andere doeleinden. AdSense Bot controleert de kwaliteit en naleving van advertenties, terwijl de Mobile Apps Android-crawler inhoud indexeert uit Android-applicaties. Elke bot heeft een eigen user-agent identificatie waarmee websitebeheerders kunnen zien welke specifieke crawler hun site bezoekt via serverlogs. Dit onderscheid is belangrijk, omdat verschillende crawlers verschillende crawlbudgetten en prioriteiten kunnen hebben, wat invloed heeft op hoe vaak ze je site bezoeken.
De Google Spider is absoluut cruciaal voor zoekmachineoptimalisatie omdat deze bepaalt of de inhoud van je website wordt ontdekt, geïndexeerd en gerangschikt in de zoekresultaten. Als Googlebot je site niet effectief kan crawlen, verschijnen je pagina’s niet in Google’s index, waardoor ze onzichtbaar zijn voor potentiële bezoekers die zoeken naar jouw producten of diensten. Daarom is technische SEO—het zorgen dat je site crawler-vriendelijk is—een van de belangrijkste fundamenten van elke succesvolle SEO-strategie.
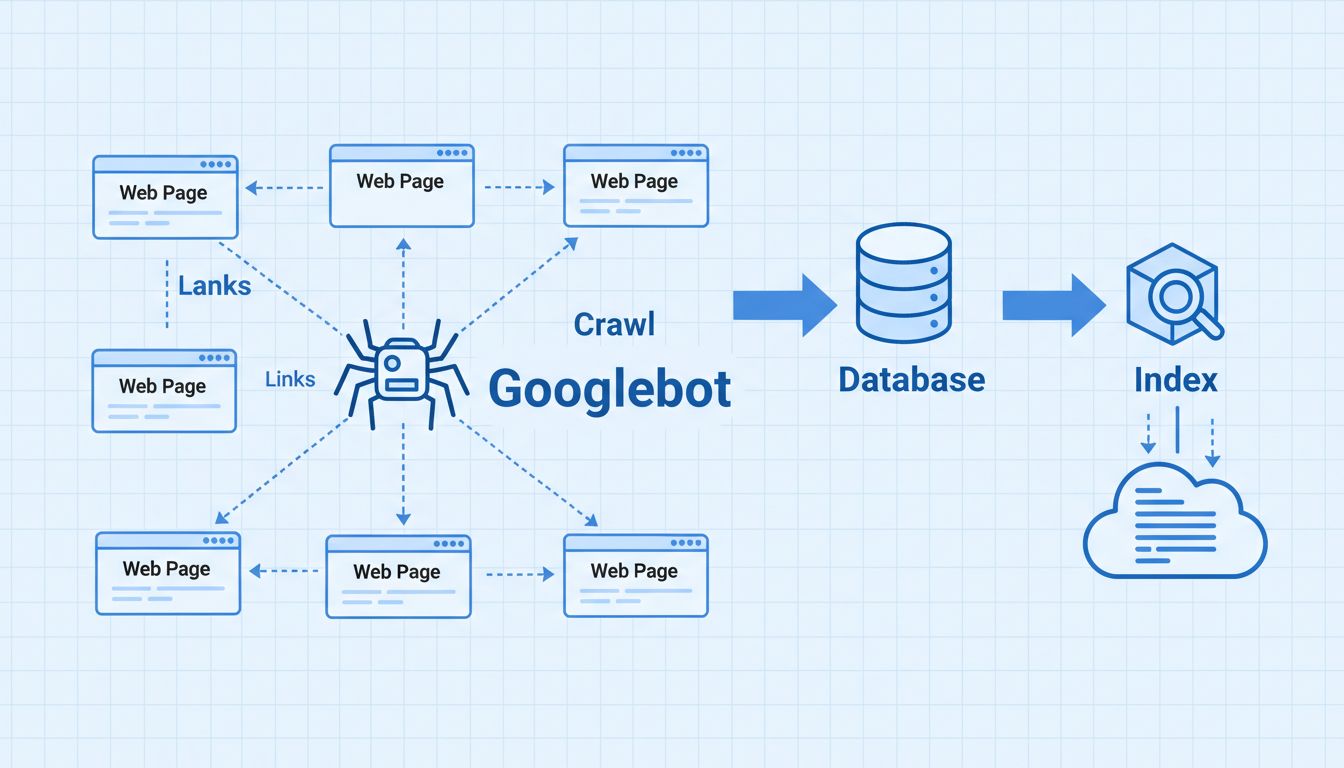
Wanneer Googlebot je website crawlt, stelt hij een enorme index samen van alle gevonden woorden en hun locatie op elke pagina, samen met HTML-informatie zoals title-tags, meta descriptions en kopstructuren. Deze geïndexeerde informatie wordt opgeslagen in Google’s database en door zoekalgoritmes gebruikt om pagina’s te rangschikken en te bepalen hoe waardevol je content is voor specifieke zoekopdrachten. Hoe efficiënter Googlebot je site kan crawlen, hoe vaker hij terugkomt en hoe sneller nieuwe content wordt geïndexeerd en mogelijk gerangschikt in de zoekresultaten.
Wees de eerste die op de hoogte is van nieuwe functies en productupdates.
Om ervoor te zorgen dat Googlebot je website effectief en efficiënt kan crawlen, moet je verschillende technische best practices toepassen. Zorg allereerst voor een duidelijke en logische sitestructuur met goede navigatie, zodat de crawler eenvoudig alle belangrijke pagina’s kan ontdekken. Interne links moeten strategisch en relevant zijn, met beschrijvende anchorteksten die zowel gebruikers als crawlers helpen de context van gelinkte pagina’s te begrijpen. Je website moet snel laden, aangezien paginasnelheid invloed heeft op de crawl-efficiëntie en hoeveel van je site Googlebot kan crawlen binnen het toegewezen crawlbudget.
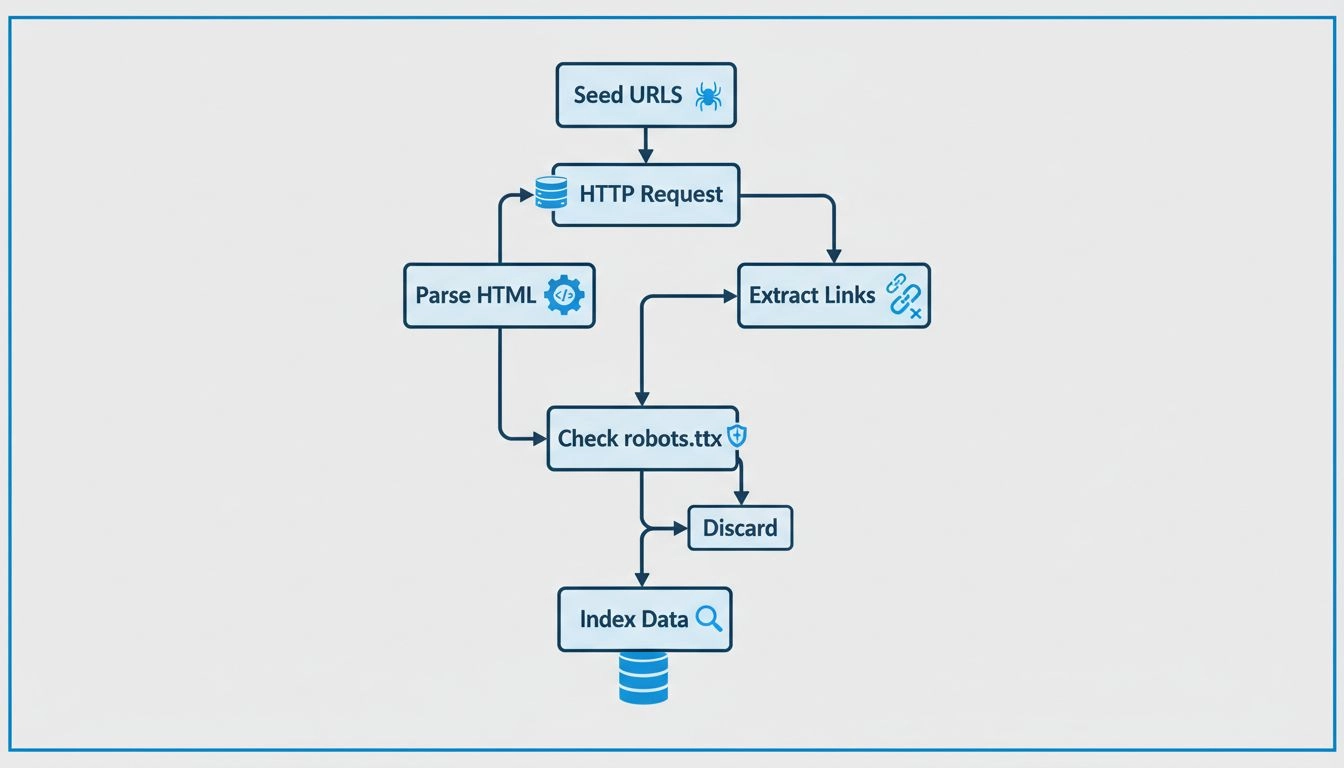
Maak en dien een XML-sitemap in bij Google Search Console, die Googlebot een volledig overzicht biedt van alle pagina’s die je geïndexeerd wilt hebben. Dit is vooral belangrijk voor grote websites of sites met pagina’s die niet eenvoudig via interne links te vinden zijn. Zorg er daarnaast voor dat je robots.txt-bestand correct is geconfigureerd zodat Googlebot toegang heeft tot de pagina’s die je wilt laten indexeren, terwijl toegang tot gevoelige of dubbele content wordt geblokkeerd. Wees echter voorzichtig dat je niet per ongeluk belangrijke pagina’s blokkeert, want dan worden deze helemaal niet geïndexeerd.
Google Search Console is een essentieel hulpmiddel om te monitoren hoe Googlebot met je website omgaat en eventuele crawlproblemen te identificeren die correcte indexering kunnen verhinderen. De Crawlstatistieken-sectie geeft gedetailleerd inzicht in hoeveel pagina’s Googlebot heeft gecrawld, hoeveel tijd hij aan het crawlen van je site heeft besteed en hoeveel fouten hij is tegengekomen. Je kunt de gemiddelde responstijd van je server zien, wat direct invloed heeft op hoe efficiënt Googlebot je pagina’s kan crawlen—langzamere servers betekenen minder gecrawlde pagina’s in dezelfde periode.
Het Dekking-rapport in Google Search Console toont welke pagina’s succesvol zijn geïndexeerd, welke pagina’s fouten hebben waardoor indexering wordt voorkomen en welke pagina’s zijn uitgesloten van de index. Deze informatie is van onschatbare waarde voor het opsporen van technische problemen zoals gebroken links, serverfouten of pagina’s die door robots.txt worden geblokkeerd zonder dat je dat bedoelt. Je kunt ook de URL-inspectie-tool gebruiken om te testen hoe Googlebot een specifieke pagina ziet, inclusief of hij JavaScript-inhoud kan weergeven en toegang heeft tot alle benodigde bronnen om de pagina correct weer te geven.
Elke website heeft een “crawlbudget”—het aantal pagina’s dat Googlebot binnen een bepaalde periode op je site zal crawlen. Voor de meeste websites is crawlbudget geen beperkende factor, maar voor zeer grote sites met duizenden of miljoenen pagina’s wordt het optimaliseren van het crawlbudget belangrijk. Google verdeelt het crawlbudget op basis van twee factoren: crawlcapaciteit (hoeveel je server aankan) en crawldemanda (hoe belangrijk Google je site vindt). Door je site sneller te maken en crawl-fouten op te lossen verhoog je de crawlcapaciteit; het creëren van kwalitatieve, regelmatig bijgewerkte content verhoogt de crawldemanda.
Om je crawlbudget te optimaliseren, elimineer je dubbele content die crawlresources verspilt, repareer je gebroken links en redirectketens en verwijder je pagina’s die geen waarde bieden aan gebruikers. Vermijd het blokkeren van belangrijke pagina’s met robots.txt of noindex-tags en zorg voor een sitestructuur waarbij Googlebot alle belangrijke pagina’s binnen enkele klikken vanaf de homepage kan ontdekken. Door regelmatig je XML-sitemap bij te werken en verouderde pagina’s te verwijderen, help je Googlebot zich te concentreren op content die het belangrijkst is voor je bedrijf.
Website-eigenaren krijgen vaak te maken met verschillende problemen die voorkomen dat Googlebot hun sites effectief kan crawlen. Serverfouten (5xx-statuscodes) geven aan dat je server moeite heeft met het beantwoorden van verzoeken, wat kan voorkomen dat pagina’s worden geïndexeerd. Redirectketens—waarbij één pagina naar een andere doorverwijst, die weer naar een derde verwijst—verspillen crawlbudget en vertragen het indexeringsproces. Geblokkeerde bronnen, zoals CSS- of JavaScript-bestanden die worden geblokkeerd door robots.txt, kunnen voorkomen dat Googlebot je pagina’s correct weergeeft en begrijpt.
Soft 404-fouten ontstaan wanneer een pagina een 200-statuscode (succes) teruggeeft, maar weinig of geen echte inhoud bevat, waardoor Googlebot in de war raakt of de pagina wel of niet geïndexeerd moet worden. Noindex-tags die per ongeluk op belangrijke pagina’s zijn toegepast, voorkomen dat deze in de zoekresultaten verschijnen. Langzame laadtijden verminderen het aantal pagina’s dat Googlebot binnen het toegewezen budget kan crawlen. Om deze problemen aan te pakken, audit je je website regelmatig met Google Search Console, controleer je serverlogs op crawl-fouten en gebruik je tools zoals Screaming Frog om technische problemen te identificeren voordat ze je zichtbaarheid in zoekmachines beïnvloeden.
In 2025 blijft de Google Spider net zo belangrijk als voorheen, al is de rol inmiddels geëvolueerd om nieuwe technologieën en contentformaten te ondersteunen. Googlebot kan nu JavaScript-rendering aan, wat betekent dat hij content kan crawlen en indexeren die dynamisch door JavaScript-frameworks wordt gegenereerd. Ook verwerkt hij gestructureerde gegevens (Schema.org) om pagina-inhoud beter te begrijpen en uitgebreide zoekresultaten te tonen. Mobile-first indexing betekent dat Googlebot prioriteit geeft aan het crawlen en indexeren van de mobiele versie van je website, waardoor mobiele optimalisatie essentieel is voor SEO-succes.
De spider speelt ook een cruciale rol bij het detecteren en bestrijden van spam, het identificeren van gehackte content en het waarborgen dat zoekresultaten relevant en betrouwbaar blijven. Naarmate zoekmachines zich blijven ontwikkelen met AI- en machine learning-technologieën, worden de crawl- en indexeerfuncties van Googlebot steeds geavanceerder, waardoor Google gebruikersintentie beter kan begrijpen en meer accurate zoekresultaten kan leveren. Begrijpen hoe Googlebot werkt en je website hierop optimaliseren blijft een van de meest fundamentele aspecten van SEO-strategie.
Net zoals Google Spider je content crawlt en indexeert, helpt PostAffiliatePro je bij het tracken en optimaliseren van je affiliate marketing prestaties. Monitor elke klik, conversie en commissie met ons toonaangevende affiliate management platform.
Crawlers verzamelen data en informatie van het internet door websites te bezoeken en pagina's te lezen. Ontdek meer over hun werking.
Leer hoe webcrawlers werken, van seed-URL's tot indexering. Begrijp het technische proces, de verschillende typen crawlers, robots.txt-regels en hoe crawlers SE...
Spiders zijn bots die worden ingezet voor spamdoeleinden en kunnen grote problemen veroorzaken voor je bedrijf. Lees meer over ze in het artikel.
Sluit u aan bij onze gemeenschap van tevreden klanten en bied uitstekende klantenservice met Post Affiliate Pro.
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.