
Wat betekent indexeren in SEO?
Ontdek wat SEO-indexering betekent, hoe het werkt en waarom het cruciaal is voor de zoekzichtbaarheid van je website. Leer best practices om ervoor te zorgen da...
11 min lezen
Leer wat pagina-indexering betekent, waarom pagina’s niet door Google worden geïndexeerd en hoe je indexeringsproblemen oplost. Ontdek technische oplossingen en best practices voor 2025.
Als een pagina niet is geïndexeerd, betekent dit dat de zoekmachine deze niet aan haar database heeft toegevoegd, waardoor de pagina niet in de zoekresultaten verschijnt. Dit kan gebeuren door technische problemen zoals noindex-tags of blokkades in robots.txt, crawl-fouten, dubbele content, lage kwaliteit of simpelweg omdat de pagina nog niet is ontdekt.
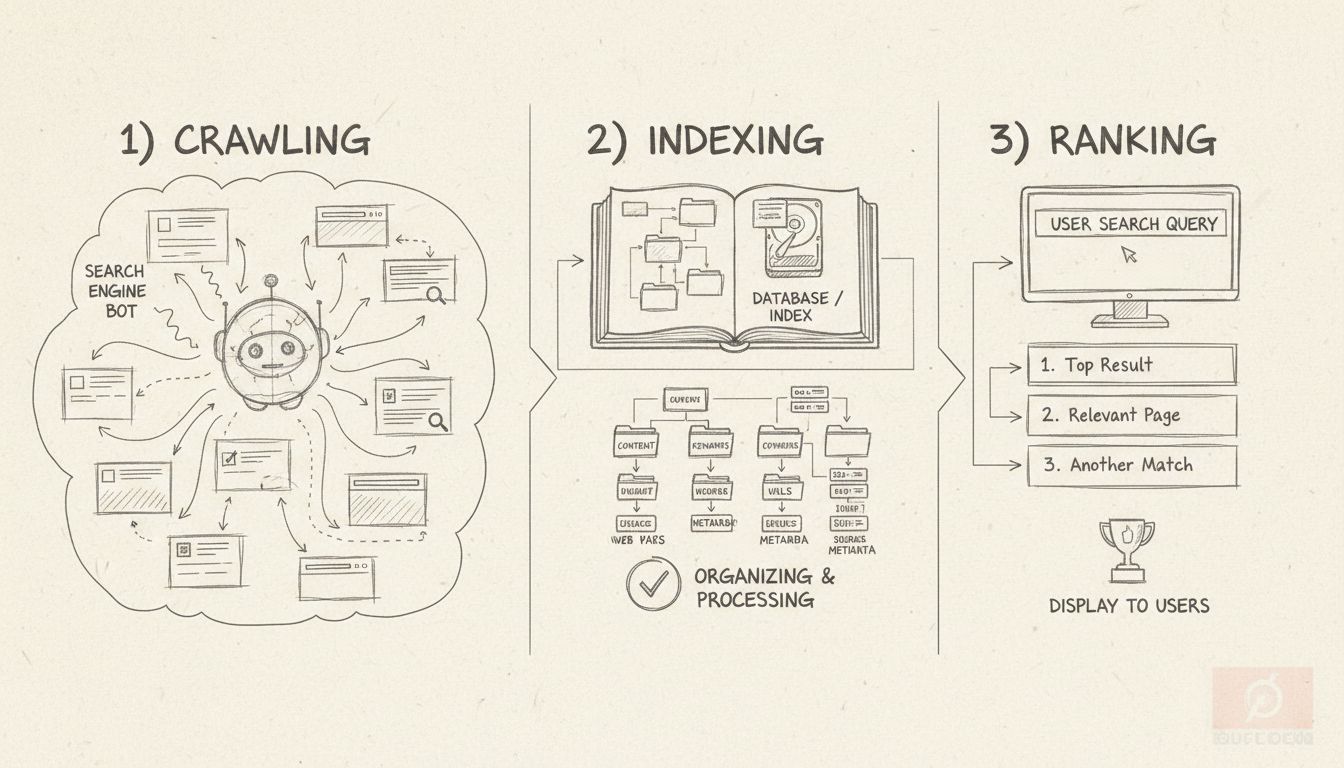
Als een pagina “niet is geïndexeerd”, betekent dit dat de zoekmachine van Google deze niet aan zijn database heeft toegevoegd, waardoor de pagina onzichtbaar is in de zoekresultaten. Dit is fundamenteel anders dan een pagina die wel bestaat maar simpelweg niet goed scoort op specifieke zoekwoorden. Het begrijpen van het verschil tussen indexeren en ranken is cruciaal voor iedereen die online content beheert of affiliate marketingcampagnes uitvoert. Indexering is de noodzakelijke eerste stap voordat een pagina überhaupt kan verschijnen in de zoekresultaten. Zonder indexering is je content in feite onzichtbaar voor zoekmachines en potentiële bezoekers die op Google vertrouwen om informatie te vinden. Het indexeringsproces kent drie belangrijke fasen: crawlen (wanneer Googlebot je pagina bezoekt), indexeren (wanneer de pagina wordt toegevoegd aan de database van Google) en ranken (wanneer de pagina verschijnt in zoekresultaten voor relevante zoekopdrachten).
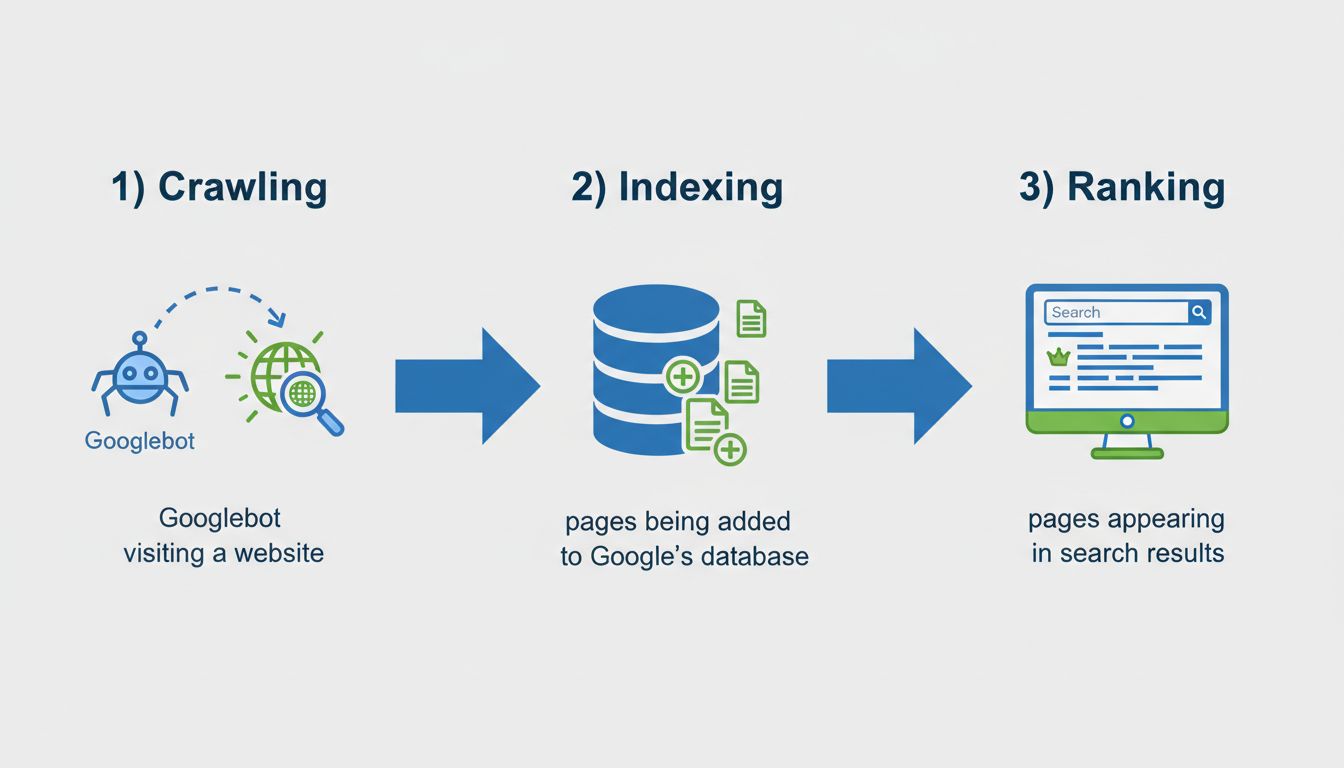
Er zijn talloze redenen waarom een pagina mogelijk niet wordt geïndexeerd, meestal vallend in drie hoofdcategorieën: technische problemen, problemen met de contentkwaliteit en ontdekbaarheidsproblemen. Door elke categorie te begrijpen, kun je indexeringsproblemen effectiever diagnosticeren en oplossen. De meest voorkomende technische belemmeringen zijn onder andere noindex-meta-tags, beperkingen in robots.txt, conflicten met canonical-tags en serverfouten. Contentgerelateerde problemen hebben meestal te maken met dunne of dubbele content, lage kwaliteit of content die niet aansluit bij de zoekintentie van gebruikers. Ontdekkingsproblemen ontstaan wanneer Google je pagina simpelweg nog niet heeft gevonden door een gebrek aan interne links, ontbrekende sitemapvermeldingen of omdat de pagina te nieuw is.
Noindex-meta-tags en blokkades in robots.txt
Een van de meest voorkomende oorzaken van niet-geïndexeerde pagina’s is de aanwezigheid van een noindex-meta-tag. Deze HTML-instructie vertelt zoekmachines expliciet dat ze een pagina niet mogen indexeren, zelfs als ze deze wel kunnen crawlen. De tag verschijnt in de broncode van de pagina als <meta name="robots" content="noindex">. Soms worden deze tags per ongeluk toegevoegd tijdens de ontwikkeling of door verkeerd ingestelde SEO-plugins. Om te controleren of je pagina een noindex-tag heeft, klik je met de rechtermuisknop op de pagina, kies je “Paginabron weergeven” en zoek je naar “noindex”. Je kunt ook de URL-inspectietool van Google Search Console gebruiken, die duidelijk aangeeft of een pagina wordt geblokkeerd door een noindex-tag.
Het robots.txt-bestand is een andere belangrijke technische barrière. Dit bestand bepaalt welke delen van je website Googlebot mag crawlen. Als je belangrijke pagina’s in robots.txt blokkeert met een “Disallow”-instructie, kan Google deze niet crawlen en dus niet indexeren. Je kunt je robots.txt-bestand controleren door naar jouwdomein.com/robots.txt te gaan in je browser. Zoek naar regels die beginnen met “Disallow” en controleer of belangrijke secties zoals /blog/ of /products/ niet per ongeluk zijn geblokkeerd.
Foutieve canonical-tags
Canonical-tags geven aan welke versie van een pagina moet worden geïndexeerd als er duplicaten bestaan. Als een canonical-tag verwijst naar de verkeerde URL—zoals je homepage of een totaal andere pagina—kan Google de pagina die je wilt laten indexeren negeren. Elke pagina zou idealiter een zelfverwijzende canonical-tag moeten hebben die naar zichzelf wijst. Je kunt dit controleren door de paginabron te bekijken en te zoeken naar link rel="canonical". Komt de URL in de canonical-tag niet overeen met de huidige pagin URL, dan is dat je probleem.
Serverfouten en HTTP-statuscodes
Wanneer Googlebot probeert een pagina te crawlen en serverfouten (5xx-statuscodes) of “pagina niet gevonden”-fouten (404-statuscodes) tegenkomt, ziet Google dit als een teken dat de pagina niet beschikbaar of functioneel is. Als deze fouten aanhouden, kan Google de pagina uiteindelijk volledig uit de index verwijderen. Je kunt de crawl-fouten van je site controleren in Google Search Console onder het rapport “Dekking”, waar pagina’s met problematische HTTP-statuscodes worden weergegeven.
Dunne en lage kwaliteit content
Google hecht steeds meer waarde aan kwaliteit en relevantie van content. Pagina’s met dunne content—dat wil zeggen onvoldoende diepgang, details of waarde—worden vaak uitgesloten van de index. Dit geldt voor pagina’s met heel weinig tekst, algemene informatie of content die de zoekvraag van gebruikers niet adequaat beantwoordt. Google’s algoritmen beoordelen of de content daadwerkelijk waarde biedt aan zoekers. Als een pagina verouderde informatie bevat, geen originele inzichten heeft of alleen maar informatie herhaalt die elders al te vinden is, kan Google besluiten dat deze niet de moeite waard is om te indexeren.
Problemen met dubbele content
Wanneer meerdere pagina’s op je site identieke of bijna identieke content bevatten, indexeert Google meestal maar één versie en markeert de rest als duplicaat. Dit komt vaak voor bij productbeschrijvingen die van fabrikanten zijn overgenomen, blogposts met minimale variaties of servicepagina’s die voor verschillende locaties worden herhaald. Dubbele content verspilt ook je crawlbudget, omdat Googlebot tijd besteedt aan het herkennen van duplicaten in plaats van het crawlen van nieuwe, unieke content.
Mismatch met zoekintentie
Pagina’s die niet aansluiten bij de zoekintentie van gebruikers worden vaak niet geïndexeerd. Bijvoorbeeld, als je een pagina maakt over “SEO-tools” maar de pagina feitelijk een blogpost is in plaats van een toolvergelijking (wat de meeste zoekers verwachten), kan Google bepalen dat de pagina niet relevant is voor die zoekopdracht en deze niet indexeren. Het begrijpen van de zoekintentie door de best scorende resultaten te analyseren vóór het maken van content is essentieel.
Weespagina’s en interne linking
Pagina’s zonder interne links die er naartoe verwijzen worden “weespagina’s” genoemd. Als een pagina nergens op je site wordt gelinkt en ook niet in je sitemap staat, kan het zijn dat Google deze nooit ontdekt. Zelfs als Google dat wel doet, geeft het ontbreken van interne links het signaal af dat de pagina niet belangrijk is, wat kan leiden tot het niet indexeren ervan. Interne links zijn paden waardoor Googlebot content ontdekt en geven ook autoriteits- en relevantiesignalen door.
Ontbrekende sitemapvermeldingen
Een sitemap is een bestand waarin de belangrijkste pagina’s van je website staan, zodat Google ze makkelijker kan vinden en prioriteren voor crawling. Als een pagina niet in je sitemap staat, is het voor Google moeilijker om deze te ontdekken, vooral als er ook geen interne links naartoe leiden. Pagina’s kunnen nog steeds worden geïndexeerd zonder in een sitemap te staan, maar opname vergroot de vindbaarheid aanzienlijk.
Beperkingen in crawlbudget
Grotere websites hebben een beperkt “crawlbudget”—het aantal pagina’s dat Google binnen een bepaalde tijd crawlt. Als je site veel pagina’s van lage kwaliteit heeft, traag laadt of overmatig veel dubbele content bevat, kan Google minder bronnen toewijzen aan het crawlen van je site. Dit betekent dat sommige pagina’s mogelijk niet snel of helemaal niet worden gecrawld en geïndexeerd.
Stel geavanceerde tracking in binnen enkele minuten. Geen creditcard vereist.
Google Search Console is het belangrijkste hulpmiddel om te achterhalen waarom pagina’s niet worden geïndexeerd. Het platform biedt gedetailleerde rapporten waarin precies staat welke pagina’s zijn geïndexeerd en waarom anderen dat niet zijn. Navigeer hiervoor naar je Search Console-property, klik in het linkermenu op “Indexering” en selecteer vervolgens “Pagina’s”. Dit rapport toont je geïndexeerde pagina’s en geeft een overzicht van de niet-geïndexeerde pagina’s met de reden.
| Type probleem | Status in GSC | Betekenis | Oplossing |
|---|---|---|---|
| Noindex-tag | Uitgesloten door ’noindex’-tag | Pagina heeft noindex-instructie | Verwijder de noindex-tag van de pagina |
| Robots.txt-blokkade | Geblokkeerd door robots.txt | Pagina uitgesloten in robots.txt | Pas robots.txt aan om crawling toe te staan |
| Dubbele content | Duplicaat zonder gekozen canonical | Meerdere vergelijkbare pagina’s | Voeg canonical-tags toe of voeg samen |
| Lage kwaliteit | Ontdekt – momenteel niet geïndexeerd | Pagina van lage waarde | Verbeter de diepgang en kwaliteit |
| Niet ontdekt | Ontdekt – momenteel niet geïndexeerd | Pagina nog niet gecrawld | Voeg interne links toe en dien sitemap in |
| Serverfout | Crawl-anomalie | Server gaf foutmelding | Los serverproblemen op en dien opnieuw in |
De URL-inspectietool is een ander krachtig hulpmiddel. Plak simpelweg een specifieke URL in de zoekbalk bovenaan Search Console en Google toont of de pagina is geïndexeerd, wanneer deze voor het laatst is gecrawld en eventuele problemen die indexering verhinderen. Als een pagina niet is geïndexeerd, legt de tool uit waarom en biedt vaak een knop “Indexering aanvragen” om Google te vragen de pagina opnieuw te crawlen.
Technische belemmeringen wegnemen
Begin met het aanpakken van technische problemen. Heeft je pagina een noindex-tag en wil je deze geïndexeerd hebben? Verwijder de tag uit de HTML van de pagina. In WordPress doe je dit meestal via je SEO-plugin (Yoast, Rank Math, All in One SEO) door het vinkje bij “Sta zoekmachines toe deze pagina te indexeren” aan te zetten. Als de pagina wordt geblokkeerd in robots.txt, pas dan het robots.txt-bestand aan zodat dat gedeelte wel toegankelijk is. Zorg bij canonical-tag-problemen dat elke pagina een zelfverwijzende canonical-tag heeft.
Contentkwaliteit verbeteren
Als je pagina wordt aangeduid als “Ontdekt – momenteel niet geïndexeerd” of “Gecrawld – momenteel niet geïndexeerd”, ligt het probleem waarschijnlijk bij de contentkwaliteit. Breid je content uit met meer uitgebreide informatie, voeg originele inzichten of data toe, zorg dat deze aansluit bij de zoekintentie en verwijder eventuele dubbele content. Zorg ervoor dat je pagina daadwerkelijk de vragen beantwoordt die gebruikers stellen bij gerelateerde zoekopdrachten.
Interne linking verbeteren
Voeg interne links toe vanuit relevante pagina’s op je site naar de niet-geïndexeerde pagina. Gebruik beschrijvende anchortekst en plaats de links op natuurlijke plekken in de content. Streef naar 2-5 interne links per pagina. Zorg er daarnaast voor dat de pagina is opgenomen in je XML-sitemap en dat je de sitemap hebt ingediend bij Google Search Console.
Indienen voor indexering
Na het aanbrengen van verbeteringen kun je de URL-inspectietool in Google Search Console gebruiken om indexering aan te vragen. Google zal de pagina opnieuw crawlen en beoordelen of deze nu wel moet worden geïndexeerd. Hoewel er geen gegarandeerde termijn is, worden pagina’s meestal binnen enkele dagen tot een paar weken opnieuw gecrawld.
Wees de eerste die op de hoogte is van nieuwe functies en productupdates.
Het behouden van een goede indexeringsstatus vraagt om voortdurende aandacht. Voer regelmatig audits uit met Google Search Console om de indexeringsstatus te monitoren. Zorg dat je robots.txt-bestand correct is ingesteld en geen belangrijke content per ongeluk blokkeert. Implementeer op de juiste wijze canonical-tags, vooral als je meerdere versies van vergelijkbare content hebt. Houd een consistente interne linkstructuur aan door gerelateerde content aan elkaar te koppelen, zodat Google de structuur van je site begrijpt. En richt je ten slotte op het creëren van hoogwaardige, originele content die echte waarde biedt voor je doelgroep. Dit is de meest effectieve langetermijnstrategie om ervoor te zorgen dat je pagina’s worden geïndexeerd én goed scoren.
Volg en beheer je affiliatecampagnes effectief met de geavanceerde tracking en analyses van PostAffiliatePro. Zorg dat je content het juiste publiek bereikt en maximaliseer je affiliate-inkomsten met ons toonaangevende platform.
Ontdek wat SEO-indexering betekent, hoe het werkt en waarom het cruciaal is voor de zoekzichtbaarheid van je website. Leer best practices om ervoor te zorgen da...
Indexering is een proces waarbij een bepaalde webpagina door crawlers wordt gevonden. Belangrijke signalen worden opgemerkt en alle gegevens worden gevolgd in d...
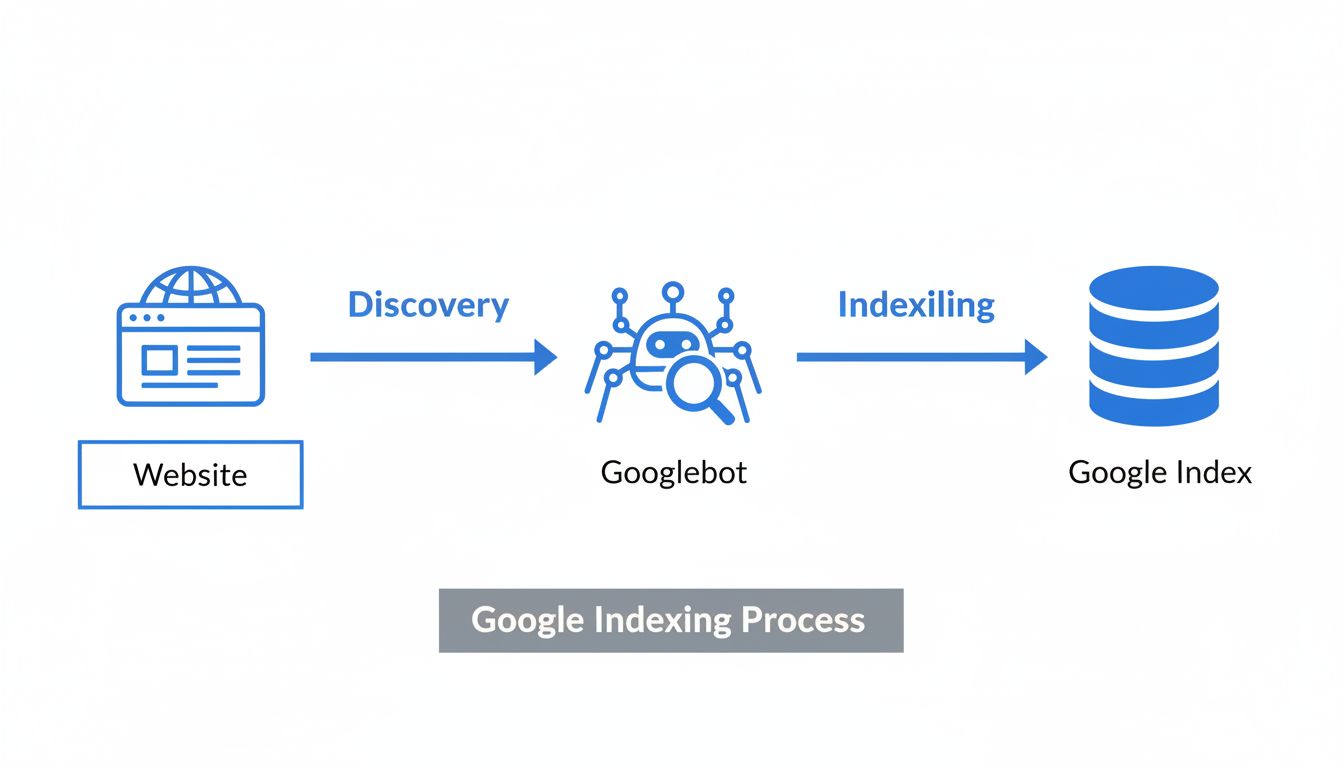
Ontdek 7 bewezen methoden om te controleren of je website is geïndexeerd door Google. Gebruik Google Search Console, site-operators, URL-inspectietools en meer ...
Sluit u aan bij onze gemeenschap van tevreden klanten en bied uitstekende klantenservice met Post Affiliate Pro.
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.