
Crawlers en hun Rol in de Zoekmachineranking
Crawlers verzamelen data en informatie van het internet door websites te bezoeken en pagina's te lezen. Ontdek meer over hun werking.
6 min lezen
SEO
Crawlers
+4
Leer hoe je zoekmachine crawlers kunt identificeren met behulp van user-agent strings, IP-adressen, aanvraagpatronen en gedragsanalyse. Essentiële gids voor webmasters en ontwikkelaars.
Zoekmachine crawlers kunnen worden geïdentificeerd via vier primaire methoden: het analyseren van de user-agent string in HTTP-headers, het verifiëren van het bron-IP-adres en reverse DNS-hostnaam, het monitoren van aanvraagpatronen voor hoge frequentie, en het onderzoeken van gedragskenmerken zoals de mogelijkheid tot het uitvoeren van JavaScript.
Zoekmachine crawlers zijn geautomatiseerde programma’s die systematisch het internet doorzoeken om webinhoud te ontdekken, analyseren en indexeren. Het identificeren van deze crawlers is cruciaal voor webmasters, ontwikkelaars en affiliate marketeers die hun websiteverkeer willen begrijpen en legitieme toegang voor zoekmachines willen waarborgen. In tegenstelling tot kwaadaardige bots die data proberen te scrapen of aanvallen uitvoeren, identificeren legitieme zoekmachine crawlers zoals Googlebot, Bingbot en anderen zichzelf via specifieke technische kenmerken die kunnen worden geverifieerd en geauthenticeerd.
Het vermogen om legitieme zoekmachine crawlers te onderscheiden van andere typen bots is in 2025 steeds belangrijker geworden naarmate het webverkeer groeit en botactiviteit geavanceerder wordt. Inzicht in de identificatiemethoden helpt u de doorzoekbaarheid van uw site te optimaliseren, uw middelen te beschermen tegen ongeautoriseerde toegang en ervoor te zorgen dat uw affiliate tracking systemen organisch zoekverkeer nauwkeurig onderscheiden van andere bronnen. PostAffiliatePro biedt geavanceerde analysemogelijkheden waarmee u verkeersbronnen nauwkeurig kunt monitoren en categoriseren, zodat uw affiliate programma accurate prestatiegegevens vastlegt.
De meest eenvoudige methode om zoekmachine crawlers te identificeren is het onderzoeken van de User-Agent string in de HTTP-verzoekheader. Elk HTTP-verzoek bevat een User-Agent header die de client identificeert die het verzoek doet, of dit nu een webbrowser, mobiele app of crawler is. Legitieme zoekmachine crawlers bevatten onderscheidende kenmerken in hun User-Agent strings die duidelijk hun oorsprong en doel aangeven. Zo identificeert Google’s crawler zichzelf als “Googlebot/2.1 (+http://www.google.com/bot.html)”, terwijl Microsoft’s Bing crawler “Bingbot/2.0 (+http://www.bing.com/bingbot.htm)” gebruikt.
Bij het analyseren van User-Agent strings moet u letten op specifieke patronen en sleutelwoorden die wijzen op legitieme zoekmachine crawlers. De User-Agent string bevat doorgaans de naam van de crawler, het versienummer en een link naar de documentatie of informatiepagina van de crawler. Legitieme crawlers van grote zoekmachines zoals Google, Bing, Yahoo en Yandex volgen consistente naamgevingsconventies en bevatten verifieerbare informatie over hun doel. U kunt deze User-Agent strings loggen in uw servertoegangslogs en vergelijken met bekende crawler-identificaties die door zoekmachines en beveiligingsorganisaties worden bijgehouden.
| Crawler Naam | User-Agent String Voorbeeld | Zoekmachine |
|---|---|---|
| Googlebot | Googlebot/2.1 (+http://www.google.com/bot.html) | |
| Bingbot | Bingbot/2.0 (+http://www.bing.com/bingbot.htm) | Microsoft Bing |
| Slurp | Slurp/cat (+http://help.yahoo.com/help/us/ysearch/slurp) | Yahoo |
| Yandexbot | Mozilla/5.0 (compatible; YandexBot/3.0) | Yandex |
| DuckDuckBot | DuckDuckBot/1.0 (+http://duckduckgo.com/duckduckbot.html) | DuckDuckGo |
Het uitsluitend vertrouwen op User-Agent strings voor crawler-identificatie kent echter beperkingen. Kwaadaardige bots kunnen User-Agent strings spoofen om zich als legitieme crawlers voor te doen, waardoor het essentieel is om deze methode te combineren met aanvullende verificatietechnieken. Bovendien kunnen sommige legitieme crawlers in bepaalde situaties generieke of aangepaste User-Agent strings gebruiken, dus kruisverwijzing met andere identificatiemethoden levert betrouwbaardere resultaten op.
Stel geavanceerde tracking in binnen enkele minuten. Geen creditcard vereist.
De tweede cruciale methode voor het identificeren van zoekmachine crawlers is het verifiëren van het bron-IP-adres en het uitvoeren van een reverse DNS lookup. Wanneer een crawler een verzoek naar uw server stuurt, komt dit van een specifiek IP-adres dat kan worden gelogd en geanalyseerd. Zoekmachines publiceren de IP-adresreeksen die hun crawlers gebruiken, zodat webmasters kunnen verifiëren of een verzoek daadwerkelijk afkomstig is van de infrastructuur van die zoekmachine. Google bijvoorbeeld onderhoudt een uitgebreide lijst met IP-adressen die door Googlebot en andere Google crawlers worden gebruikt.
Reverse DNS lookup is een bijzonder effectieve verificatietechniek waarbij het DNS-systeem wordt geraadpleegd om de hostnaam te bepalen die hoort bij een IP-adres. Wanneer u een reverse DNS lookup uitvoert op een IP-adres dat beweert van Google te zijn, moet dit resolven naar een hostnaam binnen het domein van Google (zoals “crawl-66-249-64-1.googlebot.com”). Deze hostnaam kan vervolgens worden geverifieerd via een forward DNS lookup om te bevestigen dat de hostnaam naar hetzelfde IP-adres verwijst, wat een bidirectionele verificatie oplevert. Dit tweezijdige verificatieproces maakt het zeer moeilijk voor kwaadwillenden om crawler-identiteit te spoofen, omdat zij zowel het IP-adres als de bijbehorende DNS-records moeten controleren.
De officiële documentatie van Google raadt deze verificatiemethode aan als de meest betrouwbare manier om Googlebot-verzoeken te bevestigen. Het proces houdt in dat u controleert of de reverse DNS-hostnaam overeenkomt met het domeinpatroon van Google en vervolgens verifieert dat een forward DNS lookup van die hostnaam hetzelfde IP-adres oplevert. Deze methode is vooral waardevol voor websites met veel verkeer en affiliate netwerken die een nauwkeurige verkeersattributie willen waarborgen en willen voorkomen dat frauduleuze botactiviteiten als legitiem zoekverkeer worden meegeteld.
Analyse van aanvraagpatronen geeft waardevol inzicht in het gedrag van crawlers door te onderzoeken hoe verzoeken over de tijd en over de bronnen van uw website verspreid zijn. Legitieme zoekmachine crawlers volgen voorspelbare patronen die aanzienlijk verschillen van menselijk surfgedrag of kwaadaardige botactiviteiten. Crawlers doen doorgaans verzoeken op consistente intervallen, volgen een logisch traversiepatroon door de URL-structuur van uw site en respecteren de richtlijnen in uw robots.txt-bestand. Door deze patronen te monitoren, kunt u legitieme crawlers identificeren en onderscheiden van verdachte activiteit.
Bij het analyseren van aanvraagpatronen let u op verschillende belangrijke kenmerken die wijzen op legitiem crawlergedrag. Kijk allereerst naar de frequentie en spreiding van de verzoeken—legitieme crawlers spreiden hun verzoeken doorgaans om overbelasting van uw server te voorkomen en volgen vaak exponentiële backoff-algoritmen die hun snelheid verlagen bij HTTP 500-fouten of andere signalen van serverstress. Analyseer ten tweede het URL-traversiepatroon—legitieme crawlers volgen systematisch links en respecteren de sitestructuur, terwijl kwaadaardige bots vaak willekeurige of sequentiële verzoeken doen naar niet-bestaande of niet-gelinkte URL’s. Ten derde, monitor het type aangevraagde bronnen—legitieme crawlers vragen doorgaans HTML-pagina’s, CSS-bestanden en JavaScript-bestanden op die nodig zijn om pagina’s weer te geven, terwijl ze onnodige verzoeken aan binaire bestanden of gevoelige mappen vermijden.
U kunt monitoring van aanvraagpatronen implementeren door uw serverlogs te analyseren en clusters van verzoeken te identificeren die gemeenschappelijke kenmerken delen. Tools zoals webanalyseplatforms en serverlog-analyse software kunnen dit proces automatiseren door ongebruikelijke patronen te signaleren. Bijvoorbeeld, als één IP-adres 1.000 verzoeken per minuut doet naar verschillende productpagina’s in een sequentieel patroon, is de kans groot dat het een crawler betreft. Legitieme zoekmachine crawlers doen verzoeken daarentegen meestal met een veel lagere frequentie, waarbij de verzoeken vaak enkele seconden uit elkaar liggen om serverbronnen te sparen en rate-limiting mechanismen te voorkomen.
Wees de eerste die op de hoogte is van nieuwe functies en productupdates.
Gedragsanalyse onderzoekt hoe crawlers omgaan met de content en technologie van uw website en biedt inzichten die legitieme zoekmachine crawlers onderscheiden van andere typen bots. Een van de belangrijkste gedragskenmerken is de mogelijkheid tot het uitvoeren van JavaScript. Moderne zoekmachines zoals Google renderen pagina’s met een headless browser (vergelijkbaar met Chrome) om JavaScript uit te voeren en dynamisch gegenereerde inhoud te bereiken. Dit betekent dat legitieme crawlers JavaScript-code op uw pagina’s uitvoeren, terwijl veel kwaadaardige bots of eenvoudige scrapers dit niet kunnen of niet doen.
U kunt JavaScript-uitvoering detecteren door trackingcode in te voegen die alleen wordt geactiveerd wanneer JavaScript is ingeschakeld en functioneel is. Als een verzoek uw pagina bezoekt maar geen JavaScript-afhankelijke tracking activeert of geen dynamisch gegenereerde content laadt, duidt dit erop dat de aanvrager mogelijk geen moderne zoekmachine crawler is. Daarnaast laden legitieme crawlers doorgaans alle bronnen die nodig zijn om een pagina volledig weer te geven, inclusief afbeeldingen, stylesheets en JavaScript-bestanden, terwijl eenvoudige bots vaak alleen het HTML-bestand opvragen zonder ondersteunende bronnen te laden.
Een ander belangrijk gedragskenmerk is hoe crawlers omgaan met interactieve elementen en formulierinvoer. Legitieme zoekmachine crawlers vullen geen formulieren in, klikken geen knoppen aan en gaan niet om met dynamische content op een manier die ongewenste neveneffecten veroorzaakt, zoals het plaatsen van bestellingen of het wijzigen van gegevens. Ze richten zich op het lezen en analyseren van content in plaats van ermee te interacteren. Kwaadaardige bots daarentegen proberen vaak interactie met formulieren, verzenden data of starten acties die uw website kunnen schaden of informatie kunnen stelen. Door deze gedragskenmerken te monitoren, kunt u verzoeken identificeren die ongeoorloofde interacties proberen en ze onderscheiden van legitieme crawleractiviteiten.
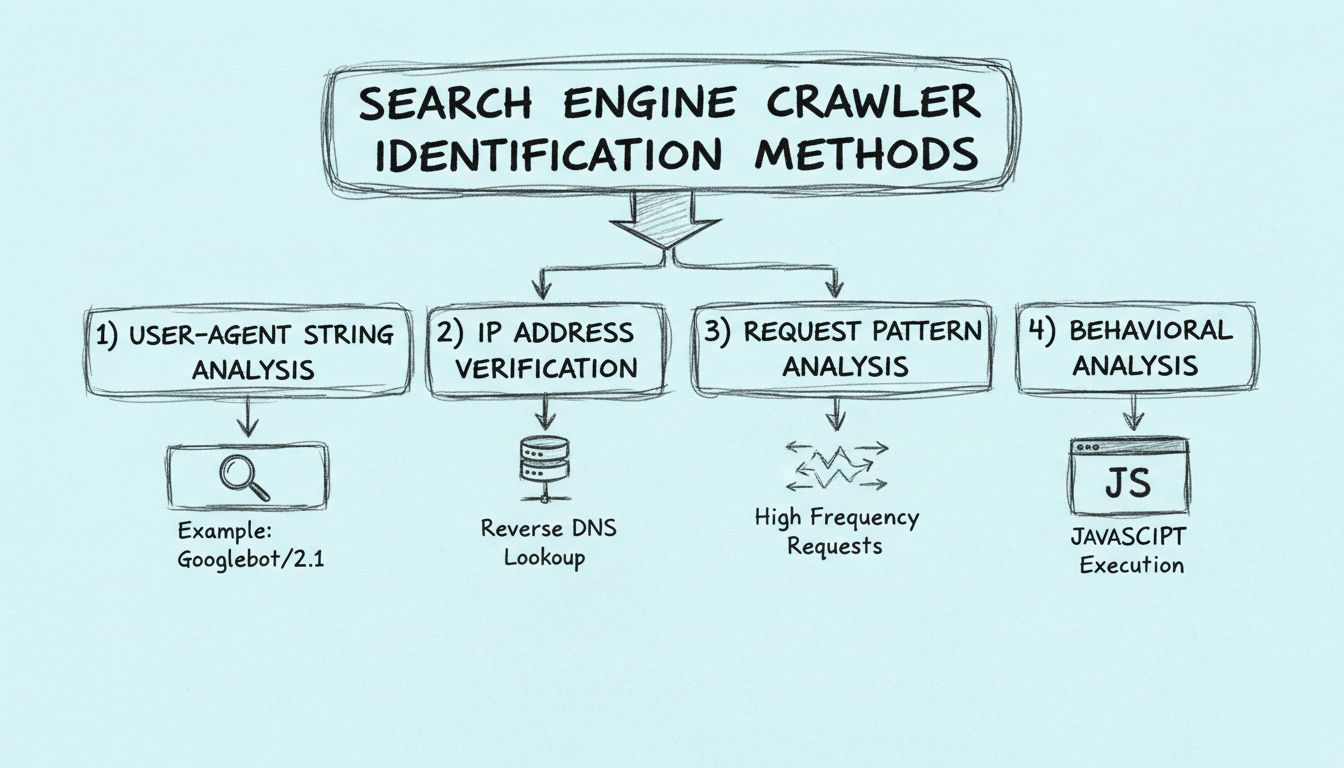
De meest effectieve benadering van crawler-identificatie combineert alle vier methoden in een uitgebreide verificatieworkflow. In plaats van te vertrouwen op één enkele identificatiemethode, biedt het implementeren van een gelaagd verificatiesysteem robuuste bescherming tegen gespoofte crawlers en zorgt het voor een nauwkeurige verkeersattributie. Begin met het vastleggen van de User-Agent string en het IP-adres van elk verzoek en vergelijk deze vervolgens met bekende crawlerdatabases van zoekmachines en beveiligingsorganisaties. Voer daarna een reverse DNS lookup uit om te controleren of de hostnaam van het IP-adres overeenkomt met het domein van de opgegeven zoekmachine. Analyseer tot slot het aanvraagpatroon en de gedragskenmerken om te waarborgen dat de activiteit overeenkomt met legitiem crawlergedrag.
Deze meerlagige aanpak is vooral belangrijk voor affiliate netwerken en performance marketing platformen zoals PostAffiliatePro, waar accurate verkeersattributie direct invloed heeft op commissieberekeningen en programmabetrouwbaarheid. Door uitgebreide crawler-identificatie te implementeren, kunt u ervoor zorgen dat uw affiliate tracking systemen legitiem zoekmachineverkeer, betaald advertentieverkeer en organisch gebruikersverkeer nauwkeurig onderscheiden. Deze precisie maakt betere prestatie-analyses, nauwkeurigere ROI-berekeningen en verbeterde fraudedetectie mogelijk.
Moderne webinfrastructuur vereist geavanceerde crawler-identificatiesystemen die de complexiteit van hedendaags webverkeer aankunnen. Ten eerste, onderhoud een bijgewerkte lijst van legitieme crawler-IP-adressen en User-Agent strings door u te abonneren op officiële meldingen van grote zoekmachines. Google, Bing en andere zoekmachines publiceren updates wanneer zij nieuwe crawlers toevoegen of hun infrastructuur wijzigen, en door hiervan op de hoogte te blijven blijven uw identificatiesystemen actueel. Ten tweede, implementeer server-side logging die alle relevante aanvraagmetadata vastlegt, waaronder User-Agent strings, IP-adressen, tijdstempels van aanvragen en aangevraagde bronnen. Deze gegevens vormen de basis voor patroonanalyse en gedragsmonitoring.
Ten derde, overweeg het implementeren van een crawler-verificatie-API of -dienst die crawler-identiteit realtime automatisch valideert. Veel beveiligings- en analyseplatforms bieden tegenwoordig crawler-identificatiediensten die up-to-date databases van legitieme crawlers bijhouden en verzoeken hiertegen kunnen verifiëren. Ten vierde, stel duidelijke beleidsregels op voor het omgaan met niet-geïdentificeerde of verdachte crawleractiviteit. U kunt ervoor kiezen deze verzoeken normaal te bedienen terwijl u ze logt voor analyse, of rate limiting toepassen om uitputting van bronnen te voorkomen. Tot slot, beoordeel en actualiseer regelmatig uw crawler-identificatieregels en drempelwaarden op basis van geobserveerde verkeerspatronen en opkomende dreigingen. Het landschap van webcrawlers blijft zich ontwikkelen en uw identificatiesystemen dienen zich hierop aan te passen om effectief te blijven.
Het identificeren van zoekmachine crawlers vereist een grondig begrip van meerdere verificatiemethoden en het vermogen deze te combineren tot een effectief detectiesysteem. Door het analyseren van User-Agent strings, het verifiëren van IP-adressen via reverse DNS lookups, het monitoren van aanvraagpatronen en het onderzoeken van gedragskenmerken, kunt u legitieme zoekmachine crawlers betrouwbaar onderscheiden van andere typen bots en verkeersbronnen. Deze vaardigheid is essentieel voor webmasters, ontwikkelaars en affiliate marketeers die hun verkeersbronnen willen begrijpen en nauwkeurige prestatiebewaking willen waarborgen. De geavanceerde analyse- en verkeersmonitoring mogelijkheden van PostAffiliatePro helpen u deze identificatiemethoden effectief te implementeren, zodat uw affiliate programma nauwkeurige gegevens vastlegt en de programmabetrouwbaarheid handhaaft in een steeds complexer digitaal landschap.
PostAffiliatePro is de toonaangevende affiliate management software die u helpt uw affiliate netwerk nauwkeurig te volgen, beheren en optimaliseren. Identificeer legitieme verkeersbronnen en maximaliseer de prestaties van uw affiliate programma met geavanceerde analyses en realtime monitoring.
Crawlers verzamelen data en informatie van het internet door websites te bezoeken en pagina's te lezen. Ontdek meer over hun werking.
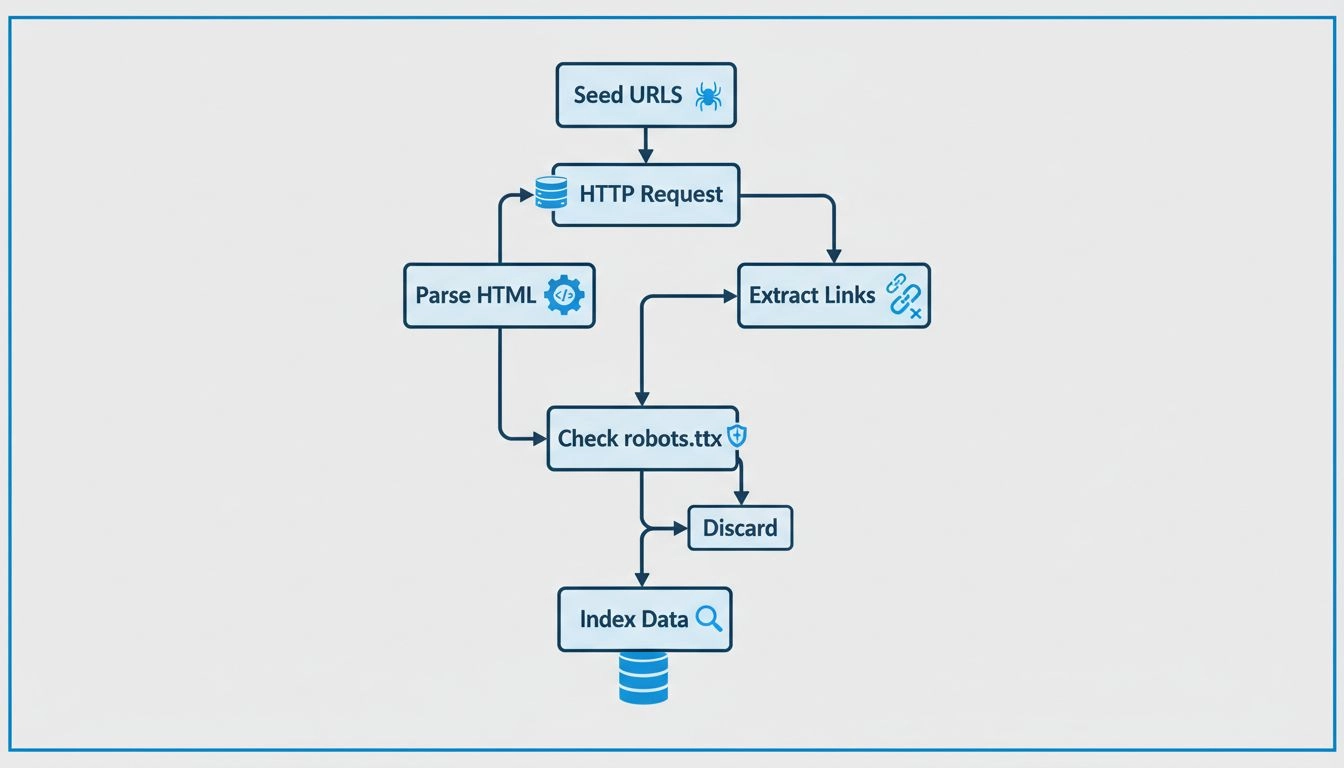
Leer hoe webcrawlers werken, van seed-URL's tot indexering. Begrijp het technische proces, de verschillende typen crawlers, robots.txt-regels en hoe crawlers SE...
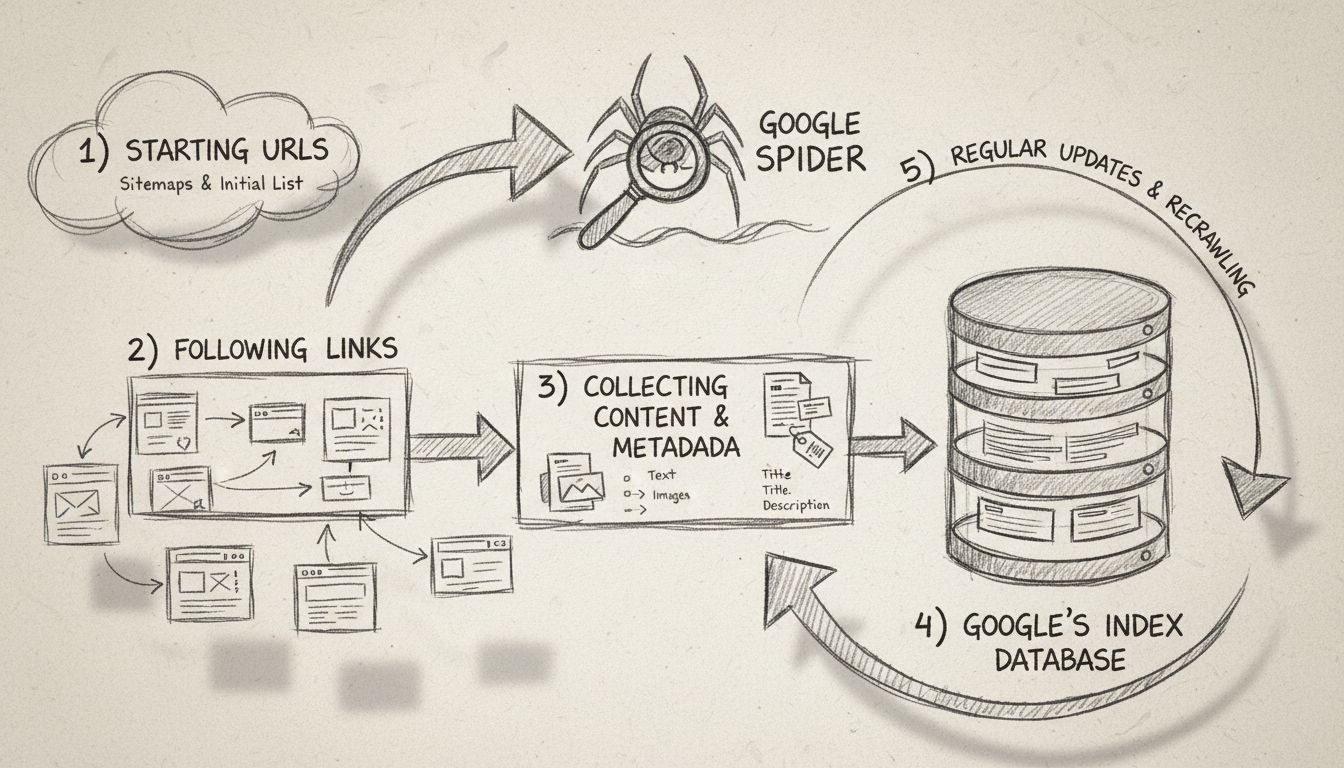
Leer wat de Google Spider (Googlebot) is, hoe deze websites crawlt en indexeert, en waarom dit essentieel is voor SEO. Ontdek hoe je jouw site kunt optimalisere...
Sluit u aan bij onze gemeenschap van tevreden klanten en bied uitstekende klantenservice met Post Affiliate Pro.
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.