
Zijn Schaduw-domeinen Goed? Risico's, Detectie & Preventiegids
Ontdek waarom schaduw-domeinen schadelijke black-hat SEO-tactieken zijn. Leer over de risico's zoals zoekmachinepenalty's, verkeersafleiding, merkonduidelijkhei...
12 min lezen
Ontdek waarom shadow pages schadelijk zijn voor SEO, hoe ze crawlbudget verspillen, duplicaat contentproblemen veroorzaken en krijg bewezen strategieën om ze van je website te verwijderen.
Ja, shadow pages zijn over het algemeen slecht voor SEO. Ze verspillen crawlbudget, veroorzaken duplicaat contentproblemen, verdunnen linkwaarde en hebben een negatieve invloed op de gebruikerservaring. Zoekmachines kunnen websites met te veel shadow pages bestraffen, wat leidt tot lagere posities en minder organische zichtbaarheid.
Shadow pages, ook wel ghost pages genoemd, zijn webpagina’s die op je website bestaan maar verborgen blijven voor gebruikers en vaak niet worden geïndexeerd door zoekmachines. Deze pagina’s ontstaan meestal onbedoeld door een slechte site-architectuur, dynamische contentgeneratie zonder goede interne links, of onvoldoende beheer van redirects. In tegenstelling tot bewust verborgen pagina’s die een specifiek doel dienen, vormen shadow pages een structureel probleem dat zoekmachines moeite hebben correct te categoriseren en te indexeren. Het fundamentele probleem is dat deze pagina’s waardevolle bronnen verbruiken zonder op een betekenisvolle manier bij te dragen aan de SEO-prestaties of gebruikerservaring van je site.
De aanwezigheid van shadow pages veroorzaakt een reeks problemen die in de loop van de tijd steeds groter worden. Wanneer zoekmachinecrawlers deze pagina’s tegenkomen, moeten ze beslissen of ze deze zullen crawlen en indexeren, wat de aandacht afleidt van belangrijkere content. Deze inefficiëntie wordt steeds problematischer naarmate je website groeit, omdat zoekmachines een beperkt crawlbudget toewijzen aan elk domein. Elke seconde die wordt besteed aan het crawlen van shadow pages, is een seconde die niet wordt besteed aan pagina’s die daadwerkelijk belangrijk zijn voor je bedrijfsdoelen en gebruikersbetrokkenheid.

Zoekmachines zoals Google wijzen een specifiek crawlbudget toe aan elke website, gebaseerd op autoriteit, grootte en updatefrequentie. Dit budget vertegenwoordigt het maximale aantal pagina’s dat Googlebot in een bepaalde periode zal crawlen. Wanneer shadow pages een deel van dit beperkte budget verbruiken, worden er minder belangrijke pagina’s tijdig gecrawld en geïndexeerd. Voor grote websites met duizenden pagina’s wordt dit een kritisch probleem dat direct invloed heeft op hoe snel nieuwe content wordt ontdekt en gerankt.
Het crawlbudgetprobleem wordt vooral ernstig wanneer shadow pages dynamisch worden gegenereerd met sessie-ID’s, trackingparameters of andere URL-variaties. Elke variatie wordt door zoekmachines gezien als een unieke pagina, waardoor het verspilde crawlbudget exponentieel toeneemt. Eén productpagina met meerdere parametercombinaties kan tientallen shadow pages genereren, die allemaal crawlbudget verbruiken dat beter gebruikt kan worden voor bedrijfskritische content. Dit betekent dat je blogposts, productpagina’s en dienstomschrijvingen weken of maanden kunnen duren om volledig geïndexeerd te worden in plaats van dagen.
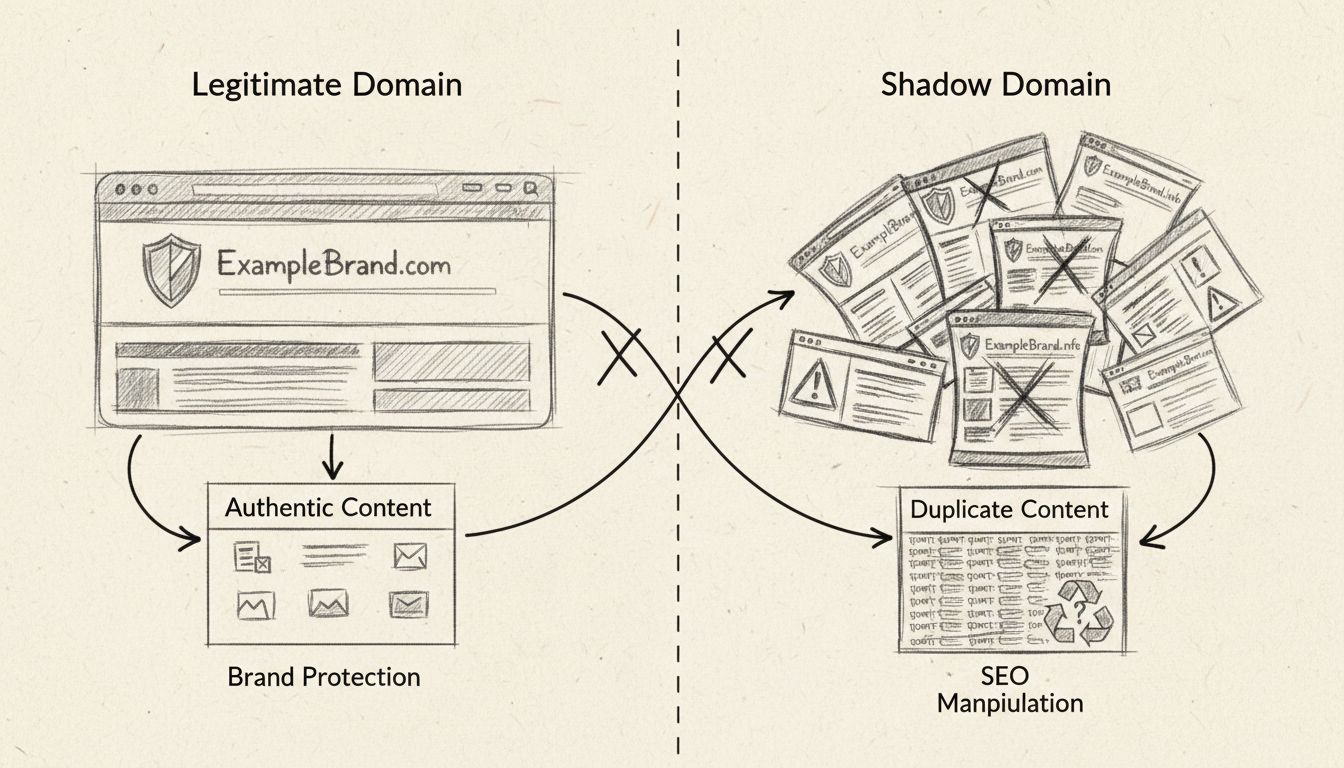
Shadow pages bevatten vaak identieke of bijna identieke content als pagina’s die al op je site zijn geïndexeerd. Wanneer zoekmachines meerdere versies van dezelfde content tegenkomen, ontstaat de vraag: welke versie moet ranken op het doelzoekwoord? Deze verwarring leidt tot keyword kannibalisatie, waarbij je eigen pagina’s met elkaar concurreren in de zoekresultaten. In plaats van de rankingkracht op één gezaghebbende pagina te bundelen, wordt je SEO-waarde verdeeld over meerdere pagina’s, wat resulteert in een zwakkere algehele prestatie.
Het duplicaat contentprobleem gaat verder dan alleen rankingverwarring. De algoritmen van Google zijn ontworpen om sites te identificeren en te bestraffen die schijnbaar opzettelijk duplicaat content aanmaken voor manipulatie. Hoewel shadow pages meestal onbedoeld zijn, kunnen de systemen van Google niet altijd onderscheid maken tussen per ongeluk aangemaakte duplicaten en opzettelijke spam. Dit betekent dat je site het risico loopt op handmatige of algoritmische straffen, die je zichtbaarheid in alle zoekresultaten aanzienlijk kunnen verminderen, niet alleen voor de gedupliceerde pagina’s.
Backlinks behoren tot de belangrijkste rankingfactoren in het algoritme van Google en vertegenwoordigen een blijk van vertrouwen van andere websites. Wanneer shadow pages backlinks verzamelen—via interne links of externe verwijzingen—wordt de linkwaarde verspreid over meerdere pagina’s in plaats van geconcentreerd op je primaire content. Deze verdunning verzwakt de autoriteit van je hoofdpagina’s en vermindert hun vermogen om te ranken op concurrerende zoekwoorden.
Interne linkstructuur wordt bijzonder problematisch met shadow pages. Als je site-architectuur meerdere URL’s voor dezelfde content creëert en sommige van deze URL’s interne links ontvangen terwijl andere dat niet doen, splits je in feite je linkwaarde. Een pagina die tien interne links zou moeten krijgen, ontvangt er misschien vijf, terwijl de shadow page-variant de andere vijf krijgt. Deze fragmentatie voorkomt dat één pagina voldoende autoriteit opbouwt om effectief te ranken op waardevolle zoekwoorden.
Stel geavanceerde tracking in binnen enkele minuten. Geen creditcard vereist.
Begrijpen hoe shadow pages ontstaan is essentieel om ze te voorkomen. Dynamische URL-parameters zijn een van de meest voorkomende oorzaken, waarbij sessie-ID’s, trackingcodes of gebruikersvoorkeuren unieke URL’s creëren voor identieke content. Webshops hebben hier vaak moeite mee als productfilters, sorteermogelijkheden of weergavevoorkeuren nieuwe URL’s genereren. Contentmanagementsystemen kunnen soms shadow pages aanmaken via paginatieparameters, printvriendelijke versies of mobiele URL’s die niet goed zijn geconsolideerd met canonieke tags.
Onjuiste implementatie van redirects veroorzaakt ook shadow pages. Wanneer websites content migreren, URL-structuren wijzigen of pagina’s samenvoegen, moeten oude URL’s met 301-redirects naar de nieuwe verwijzen. Als deze redirects niet goed zijn geconfigureerd, kunnen zoekmachines zowel de oude als de nieuwe URL’s indexeren, met duplicaat content als gevolg. Evenzo creëren websites die geen HTTPS-redirects implementeren of www- en non-www-versies niet samenvoegen meerdere shadow pages die met elkaar concurreren om posities.
Canonieke tags geven zoekmachines aan welke versie van een pagina als de gezaghebbende moet worden beschouwd wanneer meerdere URL’s vergelijkbare of identieke content bevatten. Door een rel=“canonical”-tag toe te voegen aan shadow pages, consolideer je ranking-signalen en voorkom je dat zoekmachines crawlbudget verspillen aan duplicaatversies. De canonieke tag moet verwijzen naar de primaire versie van de pagina die je wilt laten ranken in zoekresultaten.
Een correcte implementatie van canonieke tags vereist zorgvuldige planning. Voor webshops met productfilters moet de canonieke tag op gefilterde resultaten verwijzen naar de basisproductpagina. Voor paginageerde content moet elke pagina een zelfverwijzende canonieke tag hebben, of je kunt rel=“next” en rel=“prev” gebruiken om de relatie tussen pagina’s aan te geven. Het belangrijkste is dat elke shadow page duidelijk aangeeft welke pagina de rankingwaarde moet krijgen.
De noindex-meta-tag voorkomt dat zoekmachines specifieke pagina’s indexeren, terwijl ze nog wel gecrawld en toegankelijk blijven voor gebruikers. Deze aanpak werkt goed voor pagina’s die interne doeleinden dienen maar niet in de zoekresultaten thuishoren, zoals bedankpagina’s, inlogpagina’s of interne zoekresultaten. Door noindex toe te passen op shadow pages die geen waarde bieden voor zoekgebruikers, voorkom je dat ze crawlbudget verbruiken en concurreren met je primaire content.
Het implementeren van noindex vereist zorgvuldigheid om te voorkomen dat belangrijke pagina’s per ongeluk worden geblokkeerd. Je dient je site grondig te auditen om te bepalen welke pagina’s echt niet geïndexeerd hoeven te worden. Veelvoorkomende kandidaten zijn duplicaatpagina’s, pagina’s met weinig content en pagina’s die zijn aangemaakt voor interne navigatie of trackingdoeleinden. Zodra deze zijn geïdentificeerd, voeg je de noindex-tag toe aan deze pagina’s en controleer je in Google Search Console of ze niet langer verschijnen in de zoekresultaten.
De meest effectieve langetermijnoplossing is het herstructureren van je site-architectuur om de oorzaken van shadow pages weg te nemen. Dit betekent het samenvoegen van duplicaat content tot één gezaghebbende pagina, het implementeren van correcte URL-structuren die geen onnodige variaties genereren, en ervoor zorgen dat alle belangrijke pagina’s goed gelinkt zijn vanuit de navigatie en content van je site.
Voor dynamische content kun je URL-rewriting toepassen om schone, statische URL’s te creëren die geen sessie-ID’s of trackingparameters bevatten. Gebruik consistente URL-structuren op je hele site en zorg ervoor dat alle varianten van een pagina (mobiel, desktop, printvriendelijk) dezelfde URL gebruiken met responsive design of contentonderhandeling, in plaats van aparte URL’s. Deze aanpak elimineert niet alleen shadow pages, maar verbetert ook de gebruikerservaring en maakt je site beter te crawlen en te indexeren.
Wees de eerste die op de hoogte is van nieuwe functies en productupdates.
| Tool | Doel | Belangrijkste functies |
|---|---|---|
| Google Search Console | Officiële indexatiecontrole | Toont geïndexeerde vs. uitgesloten pagina’s, crawl-fouten, dekkingsproblemen |
| Screaming Frog | Technische SEO-audit | Crawlt de hele site, identificeert duplicaat content, vindt redirect-ketens |
| Ahrefs | Uitgebreide SEO-analyse | Backlink-analyse, crawlbudget-schatting, detectie van duplicaat content |
| Semrush | Concurrentieanalyse | Site-auditfuncties, technische SEO-problemen, status van pagina-indexatie |
| Moz Pro | SEO-toolset | Crawl-diagnostiek, identificatie van duplicaat content, rank-tracking |
Regelmatige site-audits zijn essentieel om shadow pages op te sporen en te elimineren voordat ze je SEO-prestaties schaden. Google Search Console biedt de meest gezaghebbende data over welke pagina’s Google heeft ontdekt en geïndexeerd. Het dekkingsrapport toont uitgesloten pagina’s en de redenen daarvoor, wat je helpt shadow pages te identificeren die zoekmachines niet hebben geïndexeerd. In de sectie Uitgesloten vind je vaak shadow pages die zijn ontstaan door URL-parameters, paginatie of redirectproblemen.
Screaming Frog biedt een uitgebreidere crawl van je hele site en simuleert hoe zoekmachines je website zien. Deze tool kan duplicaat content, redirect-ketens, ontbrekende canonieke tags en andere technische problemen identificeren die shadow pages veroorzaken. Door regelmatig Screaming Frog-audits uit te voeren, kun je shadow page-problemen detecteren voordat ze je SEO-prestaties significant beïnvloeden. De mogelijkheid van de tool om pagina’s met vergelijkbare content te vinden helpt je duplicaten samen te voegen en je sitestructuur te verbeteren.
Het toepassen van best practices vanaf het begin voorkomt dat shadow pages een probleem worden. Gebruik altijd canonieke tags op pagina’s met vergelijkbare content, vooral op webshops met gefilterde resultaten of paginageerde content. Zorg ervoor dat je robots.txt-bestand niet per ongeluk belangrijke pagina’s blokkeert terwijl shadow pages wel gecrawld kunnen worden. Stel je sitemap.xml zo in dat alleen pagina’s die je wilt laten indexeren worden opgenomen, met uitsluiting van shadow pages en dunne content.
Stel duidelijke richtlijnen op voor URL-structuren voor je ontwikkelteam. Vermijd het gebruik van sessie-ID’s, trackingparameters of gebruikersvoorkeuren in URL’s. Implementeer deze functies in plaats daarvan via cookies of server-side sessies die geen nieuwe URL’s genereren. Voor dynamische content kun je URL-rewriting gebruiken om schone, consistente URL’s te maken die zoekmachines gemakkelijk kunnen begrijpen en indexeren.
Implementeer altijd correcte 301-redirects wanneer je URL-structuren wijzigt of pagina’s samenvoegt. Houd redirect-ketens in de gaten en zorg ervoor dat deze niet meer dan drie stappen bevatten, want overmatige redirects verspillen crawlbudget en kunnen indexatieproblemen veroorzaken. Test alle redirects regelmatig om te controleren of ze correct werken en naar de juiste bestemmingspagina’s verwijzen.
Shadow pages vormen een aanzienlijke SEO-uitdaging die je zoekzichtbaarheid en organisch verkeerspotentieel kan ondermijnen. Door crawlbudget te verspillen, duplicaat contentproblemen te veroorzaken en linkwaarde te verdunnen, voorkomen shadow pages dat je belangrijkste content de aandacht krijgt die het verdient van zoekmachines. Het goede nieuws is dat shadow pages grotendeels te voorkomen zijn met een correcte site-architectuur, implementatie van canonieke tags en regelmatige technische audits.
Actie ondernemen om shadow pages te elimineren moet een prioriteit zijn in je SEO-strategie voor 2025. Begin met het auditen van je site via Google Search Console en Screaming Frog om bestaande shadow pages op te sporen. Implementeer canonieke tags op duplicaat content, gebruik noindex-richtlijnen voor niet-essentiële pagina’s en herstructureer je site-architectuur om te voorkomen dat er nieuwe shadow pages ontstaan. Door dit technische SEO-probleem aan te pakken, verbeter je je crawlefficiëntie, bundel je je rankingkracht en bereik je uiteindelijk betere zoekzichtbaarheid en organisch verkeer voor je bedrijf.
Shadow pages en technische SEO-problemen kunnen je affiliate marketingprestaties aanzienlijk beïnvloeden. PostAffiliatePro biedt uitgebreide tracking en analyses om je te helpen SEO-problemen te identificeren en op te lossen die de zichtbaarheid en conversies van je affiliateprogramma beïnvloeden. Monitor je affiliatepagina's, volg prestatiegegevens en zorg ervoor dat al je content correct wordt geïndexeerd en geoptimaliseerd.
Ontdek waarom schaduw-domeinen schadelijke black-hat SEO-tactieken zijn. Leer over de risico's zoals zoekmachinepenalty's, verkeersafleiding, merkonduidelijkhei...
Shadowdomeinen zijn onbevoegde of kwaadaardige domeinen die legitieme websites imiteren om verkeer af te leiden, zoekmachineresultaten te manipuleren of fraudul...

Ontdek waarom SEO cloaking schadelijk is voor je website. Leer over de risico's van black hat SEO-technieken, Google-straffen en waarom white hat SEO essentieel...
Sluit u aan bij onze gemeenschap van tevreden klanten en bied uitstekende klantenservice met Post Affiliate Pro.
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.