Waarom worden webspiders computer-spiders genoemd? Inzicht in webcrawlers
Ontdek waarom webspiders computer-spiders worden genoemd en hoe ze het internet crawlen. Leer hoe zoekmachinecrawlers werken en hun belang voor SEO en affiliate marketing.
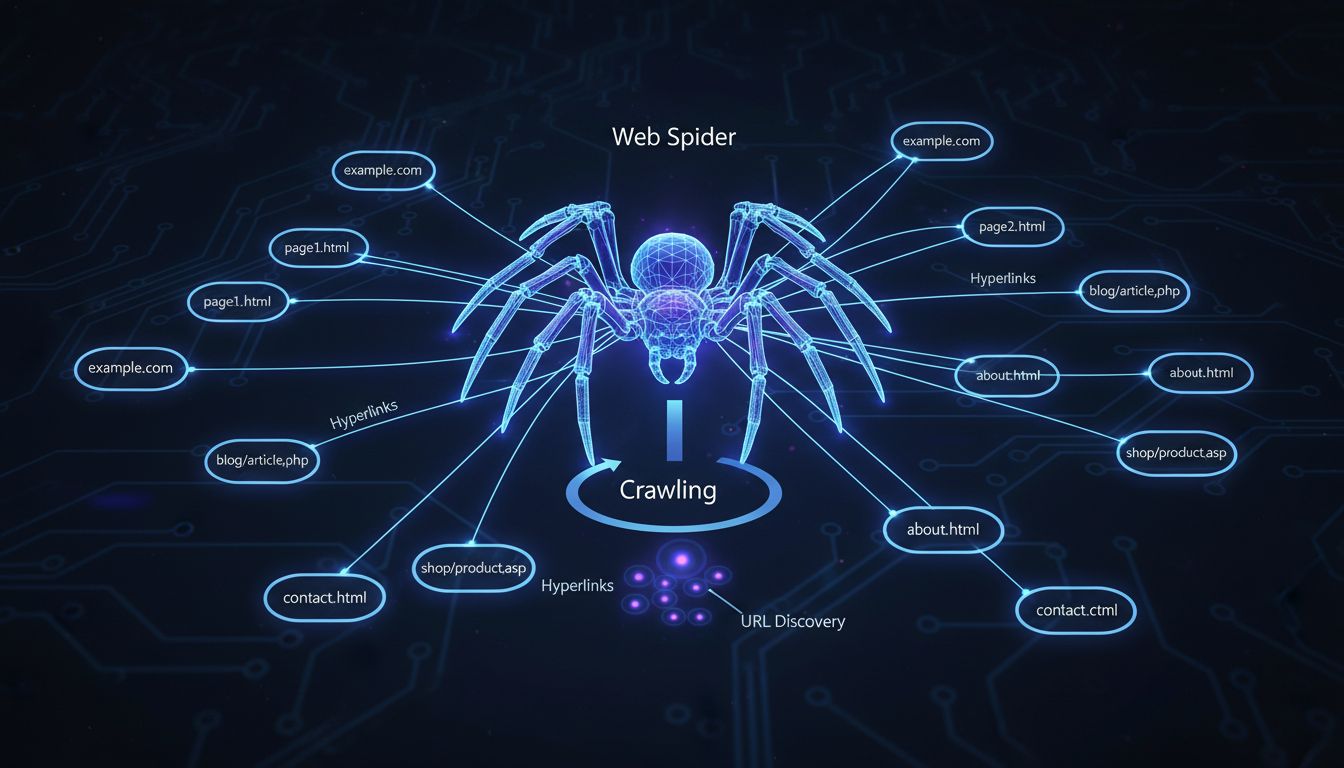
Waarom worden ze computer-spiders genoemd? Ze worden computer-spiders genoemd omdat ze het web "crawlen".
Webspiders worden computer-spiders genoemd omdat ze over het internet "kruipen" door hyperlinks van de ene naar de andere pagina te volgen, net zoals een spin over zijn web beweegt. Deze geautomatiseerde programma's verkennen systematisch websites om inhoud te ontdekken en te indexeren voor zoekmachines.
De metafoor van de spin uitgelegd
De term “computer-spider” komt voort uit een slimme analogie die perfect beschrijft hoe deze geautomatiseerde programma’s op het internet functioneren. Net zoals een echte spin over haar web beweegt door draden en verbindingen te volgen, navigeert een webspider over het internet door hyperlinks van de ene webpagina naar de andere te volgen. Deze metafoor is zo vanzelfsprekend geworden dat het nu de standaardterminologie is die wereldwijd door webontwikkelaars, SEO-professionals en digitale marketeers wordt gebruikt. De naam vangt de essentie van het gedrag van de crawler op een manier die direct begrijpelijk is voor zowel technische als niet-technische doelgroepen. Wanneer je dit fundamentele concept begrijpt, ga je waarderen hoe elegant de infrastructuur van het internet natuurlijke systemen in de natuur weerspiegelt.
Hoe webspiders het internet crawlen
Webspiders werken via een systematisch en methodisch proces dat begint met een startlijst van bekende URL’s. De crawler begint met het bezoeken van deze eerste webpagina’s en onderzoekt zorgvuldig hun inhoud en structuur. Terwijl elke pagina wordt verwerkt, identificeert de spider alle hyperlinks op die pagina en voegt deze toe aan een wachtrij van URL’s die vervolgens bezocht worden. Dit proces herhaalt zich continu, waardoor de spider steeds dieper in het web doordringt bij elke iteratie. De spider maakt feitelijk een kaart van het internet door deze verbindingen te volgen, vergelijkbaar met een ontdekkingsreiziger die nieuw terrein in kaart brengt door paden en sporen te volgen. Deze systematische aanpak zorgt ervoor dat zoekmachines elke dag miljoenen nieuwe pagina’s kunnen ontdekken en catalogiseren.
Crawler-component
Functie
Doel
URL-wachtrij
Slaat lijst op van te bezoeken pagina’s
Organiseert de crawlvolgorde
Parser
Leest pagina-inhoud en HTML
Extraheert links en metadata
Indexer
Slaat pagina-informatie op
Creëert doorzoekbare database
Scheduler
Bepaalt crawl-frequentie
Beheert resource-toewijzing
User-Agent
Identificeert de crawler
Communiceert met servers
Het technische proces achter webcrawling
Voordat een webspider zijn crawloperatie start, moeten ontwikkelaars duidelijke, vooraf gedefinieerde instructies opstellen die het gedrag van de spider sturen. Deze instructies bepalen welke pagina’s gecrawld moeten worden, hoe vaak pagina’s opnieuw bezocht worden en welke informatie van elke pagina moet worden gehaald. De crawler voert deze instructies vervolgens automatisch uit, en volgt het algoritme precies zoals geprogrammeerd. Wanneer de spider een website bezoekt, controleert hij eerst het robots.txt-bestand, een tekstbestand dat regels specificeert voor crawler-toegang. Dit protocol, bekend als het robot exclusion protocol, stelt website-eigenaren in staat hun voorkeuren te communiceren over welke delen van hun site gecrawld mogen worden en welke niet. De informatie die door de crawler wordt verzameld, hangt volledig af van de specifieke instructies die eraan zijn gegeven, waardoor de opzetfase cruciaal is voor het behalen van de gewenste resultaten.
Verschillende soorten webspiders
Webspiders komen in verschillende vormen, elk ontworpen voor specifieke doeleinden en toepassingen. Zoekmachinespiders zoals Googlebot zijn het bekendst en worden door grote zoekmachines gebruikt om webpagina’s te ontdekken en te indexeren voor zoekresultaten. Gerichte crawlers beperken hun bereik daarentegen tot specifieke onderwerpen of gebieden van het internet, en maken gedetailleerde indexen van niche-inhoud. Webanalyse-spiders helpen webmasters bij het monitoren van hun eigen websites door statistieken zoals sitebezoeken, dode links en pagina-prestaties te volgen. Prijsvergelijkingsspiders verzamelen automatisch prijsinformatie van meerdere aanbieders, zodat vergelijkingswebsites gebruikers actuele marktgegevens kunnen bieden. E-mailvalidatie-spiders controleren e-mailadressen en checken op bezorgproblemen. Elk type spider dient een specifiek doel in het digitale ecosysteem, en het begrijpen van deze verschillen helpt website-eigenaren hun sites te optimaliseren voor de juiste crawlers.
Waarom zoekmachines afhankelijk zijn van webspiders
Zoekmachines kunnen niet functioneren zonder webspiders, omdat deze geautomatiseerde programma’s verantwoordelijk zijn voor het ontdekken van nieuwe inhoud en het up-to-date houden van zoekindexen. Wanneer je een zoekopdracht uitvoert, doorzoekt de zoekmachine niet het live internet in real-time. In plaats daarvan wordt gezocht in een index die werd samengesteld door webspiders die eerder miljarden webpagina’s hebben bezocht en gecatalogiseerd. Zonder spiders zouden zoekmachines niet weten welke inhoud er op het internet bestaat of hoe deze georganiseerd moet worden voor vindbaarheid. Doordat de spider hyperlinks kan volgen, kunnen nieuwe pagina’s automatisch worden ontdekt zonder dat ze handmatig aangemeld hoeven te worden. Dit geautomatiseerde ontdekkingsproces maakt het internet doorzoekbaar en toegankelijk voor miljarden gebruikers wereldwijd. De efficiëntie en snelheid van webspiders bepalen direct hoe snel nieuwe inhoud in zoekresultaten verschijnt.
Het belang van webspiders voor SEO en digitale marketing
Voor website-eigenaren en digitale marketeers is inzicht in webspiders essentieel, omdat deze crawlers bepalen of je inhoud wordt opgenomen in zoekresultaten. Als een zoekmachine-spider je website niet kan crawlen, worden je pagina’s niet geïndexeerd en verschijnen ze niet in de zoekresultaten, ongeacht de kwaliteit van je content. Daarom focussen SEO-professionals sterk op het “crawler-vriendelijk” maken van websites door te zorgen voor een goede sitestructuur, snelle laadtijden en duidelijke navigatie. Affiliate marketeers in het bijzonder profiteren van inzicht in het gedrag van spiders, omdat dit direct invloed heeft op hoe hun affiliatepagina’s worden ontdekt en gerangschikt. PostAffiliatePro begrijpt dat succesvolle affiliateprogramma’s afhankelijk zijn van zichtbaarheid, en ons platform helpt je je affiliatenetwerk te optimaliseren zodat zoekmachine-spiders je affiliate-inhoud eenvoudig kunnen ontdekken en indexeren. Door je affiliatepagina’s toegankelijk te maken voor crawlers, vergroot je de kans dat potentiële affiliates en klanten jouw programma via organisch zoeken vinden.
Het beheren en controleren van webspider-activiteit
Website-eigenaren hebben verschillende hulpmiddelen om te beheren hoe webspiders met hun site omgaan. Het robots.txt-bestand is het primaire mechanisme om crawler-voorkeuren te communiceren, zodat je kunt aangeven welke pagina’s gecrawld mogen worden en welke niet. De noindex-meta-tag biedt extra controle door te voorkomen dat specifieke pagina’s worden geïndexeerd, zelfs als ze gecrawld worden. Voor pagina’s die wel gecrawld maar niet geïndexeerd moeten worden, kan het nofollow-attribuut op links worden gebruikt om te voorkomen dat spiders die verbindingen volgen. Website-eigenaren kunnen ook de Google Search Console en andere webmastertools gebruiken om crawler-activiteit te monitoren en eventuele problemen te identificeren die correcte indexering in de weg kunnen staan. Het is echter belangrijk op te merken dat, hoewel deze tools helpen bij het beheren van legitieme zoekmachinespiders, kwaadwillende bots en scrapers deze richtlijnen vaak negeren. Daarom implementeren veel websites extra beveiligingsmaatregelen en botmanagementsystemen om zich te beschermen tegen schadelijke crawler-activiteiten, terwijl ze nuttige spiders wel toegang geven tot hun inhoud.
Het onderscheid tussen spiders en scrapers
Hoewel webspiders en webscrapers beide automatisch gegevens van websites verzamelen, dienen ze heel verschillende doelen en hanteren ze andere ethische richtlijnen. Webspiders, met name die van zoekmachines, volgen het robots.txt-protocol en respecteren de voorkeuren van website-eigenaren over welke inhoud gecrawld mag worden. Scrapers daarentegen negeren deze richtlijnen vaak en kopiëren volledige pagina’s met inhoud om elders te publiceren, wat kan leiden tot schending van auteursrechten en diefstal van intellectueel eigendom. Spiders verzamelen en organiseren doorgaans alleen metadata over pagina’s, terwijl scrapers de volledige zichtbare inhoud kopiëren. Zoekmachinespiders worden over het algemeen als nuttig beschouwd omdat ze websites helpen aan meer zichtbaarheid, terwijl scrapers meestal als schadelijk worden gezien omdat ze inhoud stelen en de prestaties van websites kunnen schaden. Dit onderscheid is belangrijk voor website-eigenaren die het verschil moeten herkennen tussen legitiem crawlerverkeer en schadelijke botactiviteiten. PostAffiliatePro helpt affiliate managers bij het monitoren en beheren van verkeer naar hun affiliatepagina’s, zodat legitieme spiders toegang hebben tot je inhoud en je beschermd blijft tegen kwaadaardige scraping-activiteiten.
Maximaliseer de zichtbaarheid van je affiliatenetwerk
Net als webspiders je content ontdekken en indexeren, helpt PostAffiliatePro je om je volledige affiliatenetwerk te ontdekken en beheren. Volg elke crawler-interactie en optimaliseer de prestaties van je affiliateprogramma met ons toonaangevende platform.
Waarom worden webcrawlers 'spiders' genoemd? Inzicht in webindexeringstechnologie
Ontdek waarom webcrawlers 'spiders' worden genoemd, hoe ze werken en hun cruciale rol in zoekmachine-indexering. Leer de technische mechanismen achter webcrawli...
Wat is een Spider-computervirus? Definitie, Bedreigingen & Beschermingsgids
Ontdek wat spider-computervirussen zijn, hoe ze zich verspreiden over netwerken en ontdek effectieve beschermingsstrategieën. Uitgebreide gids voor het begrijpe...
7 min lezen
U bent in goede handen!
Sluit u aan bij onze gemeenschap van tevreden klanten en bied uitstekende klantenservice met Post Affiliate Pro.