Crawlers en hun Rol in de Zoekmachineranking
Crawlers verzamelen data en informatie van het internet door websites te bezoeken en pagina's te lezen. Ontdek meer over hun werking.
6 min lezen
SEO
Crawlers
+4
Leer hoe webcrawlers werken, van seed-URL’s tot indexering. Begrijp het technische proces, de verschillende typen crawlers, robots.txt-regels en hoe crawlers SEO en affiliate marketing beïnvloeden.
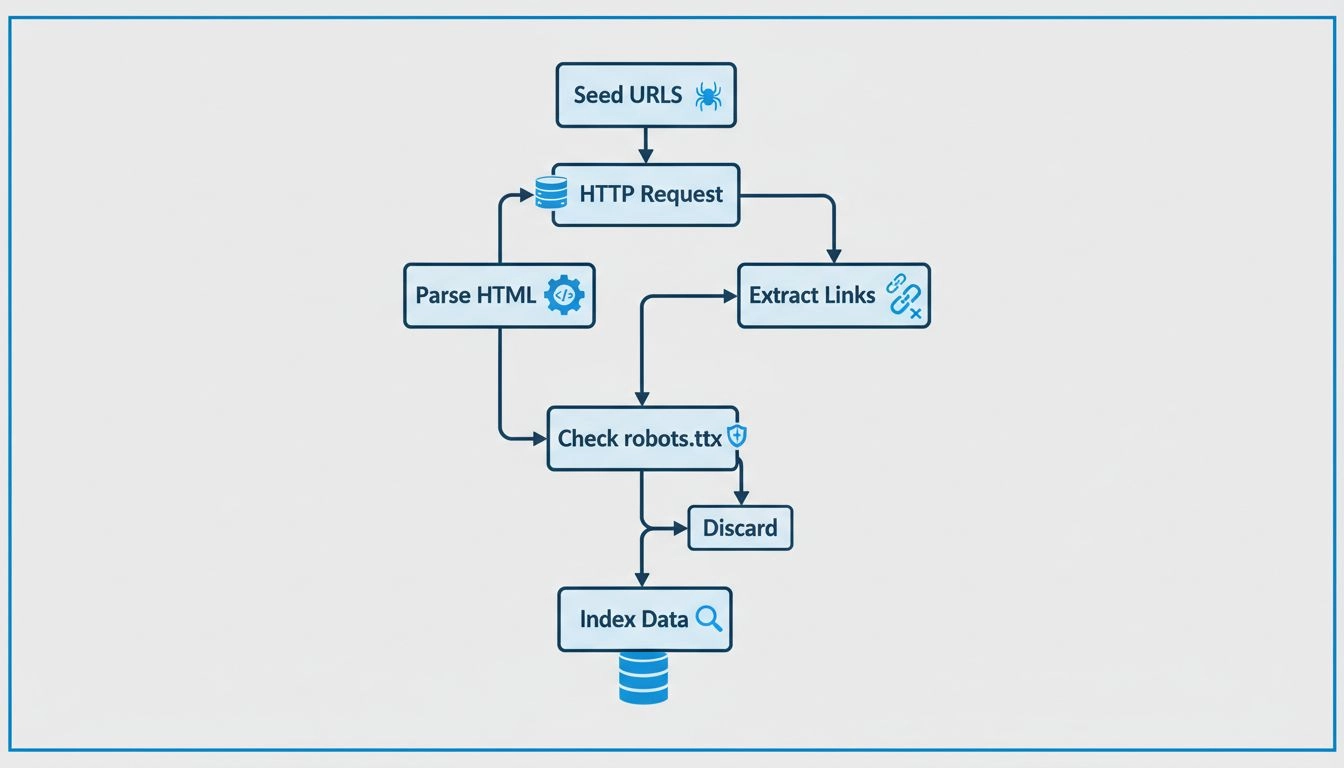
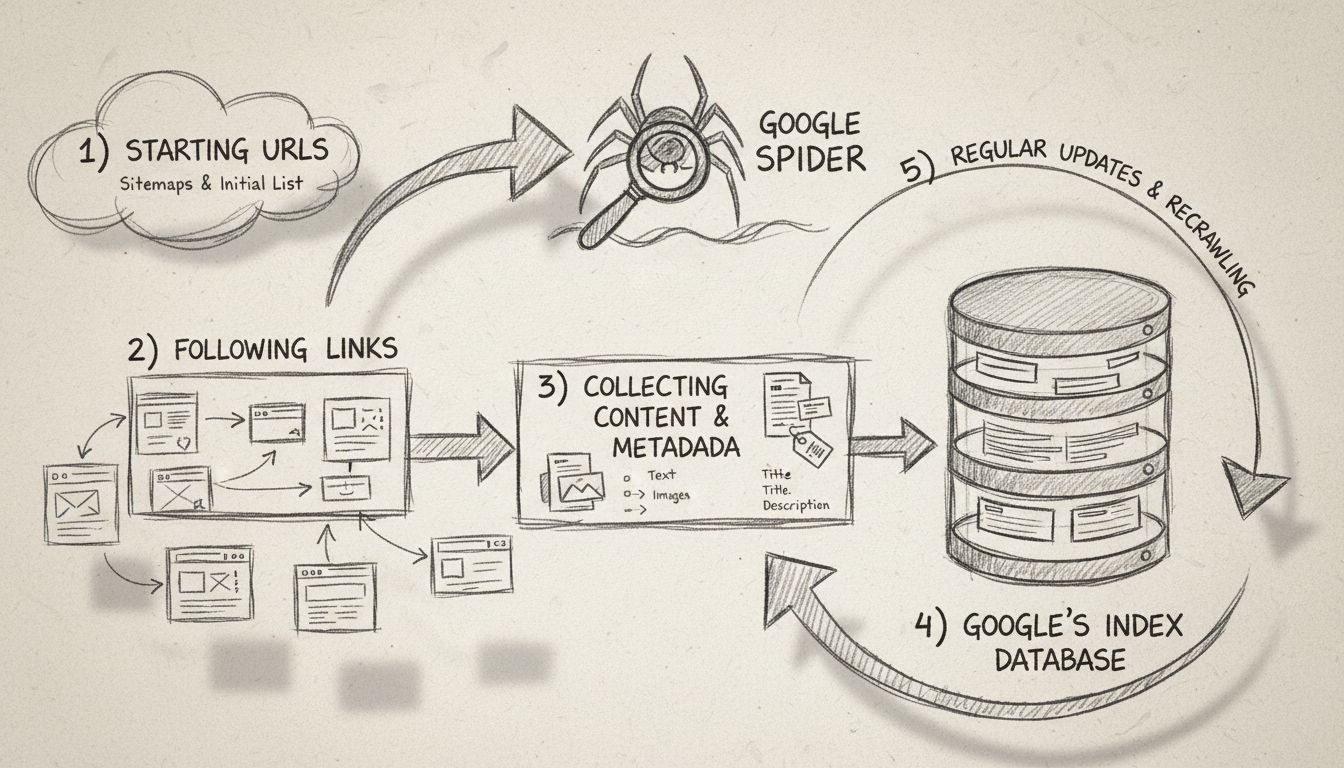
Webcrawlers werken door HTTP-verzoeken naar websites te sturen, beginnend bij seed-URL's, en volgen hyperlinks om nieuwe pagina's te ontdekken. Ze parseren HTML-inhoud om informatie te extraheren, respecteren robots.txt-regels en slaan verzamelde data op in doorzoekbare indexen. Ze bezoeken systematisch pagina's, halen metadata en links op, en herhalen dit proces om zoekmachinedatabases actueel te houden.
Webcrawlers, ook wel spiders of bots genoemd, zijn geautomatiseerde programma’s die systematisch het internet doorzoeken om webinhoud te ontdekken, downloaden en analyseren. Deze intelligente agenten vormen de ruggengraat van zoekmachine-infrastructuur en stellen platforms als Google, Bing en andere zoekdiensten in staat om uitgebreide indexen van miljarden webpagina’s op te bouwen. Het primaire doel van webcrawlers is informatie van websites verzamelen en organiseren, zodat zoekmachines snel relevante resultaten kunnen ophalen wanneer gebruikers een zoekopdracht uitvoeren. Zonder webcrawlers zouden zoekmachines geen manier hebben om nieuwe content te ontdekken of hun indexen actueel te houden met de laatste informatie online.
Het belang van webcrawlers reikt veel verder dan alleen zoekfunctionaliteit. Ze vormen de basis voor talloze digitale toepassingen, waaronder prijsvergelijkingswebsites, content-aggregators, marktonderzoekplatforms, SEO-analysetools en webarchiveringsdiensten. Voor affiliate marketeers en netwerkbeheerders zoals gebruikers van PostAffiliatePro is inzicht in het functioneren van crawlers essentieel om ervoor te zorgen dat affiliate content, productpagina’s en promotiemateriaal correct worden ontdekt en geïndexeerd door zoekmachines. Deze zichtbaarheid heeft directe invloed op organisch verkeer, leadgeneratie en uiteindelijk op affiliate commissie-inkomsten.
Webcrawlers volgen een methodisch en gestructureerd proces om het internet systematisch te verkennen. Het proces begint met seed-URL’s, bekende startpunten zoals homepage-URL’s, XML-sitemaps of eerder gecrawlde pagina’s. Deze seed-URL’s dienen als toegangspunt voor de reis van de crawler over het web. De crawler houdt een wachtrij van te bezoeken URL’s bij, vaak de “crawl frontier” genoemd, die voortdurend groeit naarmate nieuwe links worden ontdekt tijdens het crawlproces.
Wanneer een crawler een URL bereikt, stuurt hij een HTTP-verzoek naar de webserver die die pagina host. De server reageert door de HTML-inhoud van de pagina terug te sturen, vergelijkbaar met hoe een webbrowser een pagina laadt wanneer je deze bezoekt. De crawler analyseert vervolgens deze HTML-code om waardevolle informatie te extraheren, waaronder de tekstinhoud van de pagina, metatags (zoals titel en beschrijving), afbeeldingen, video’s en vooral hyperlinks naar andere pagina’s. Het extraheren van links is cruciaal omdat de crawler zo nieuwe URL’s ontdekt die nog niet zijn bezocht, die vervolgens worden toegevoegd aan de crawlwachtrij voor toekomstige bezoeken.
| Fase van het crawlerproces | Beschrijving | Belangrijkste acties |
|---|---|---|
| Initialisatie | Starten van het crawlproces | Seed-URL’s laden, crawlwachtrij initialiseren |
| Request & Retrieval | Opvragen van paginainhoud | HTTP-verzoeken sturen, HTML-antwoorden ontvangen |
| HTML-analyse | Structuur van de pagina parseren | Tekst, metadata, links, media extraheren |
| Linkextractie | Nieuwe URL’s vinden | Hyperlinks identificeren, toevoegen aan crawlwachtrij |
| robots.txt-controle | Regels van de site respecteren | Crawling-permissies verifiëren voor bezoek |
| Inhoud opslaan | Informatie bewaren | Data indexeren in doorzoekbare database |
| Prioritering | Volgende pagina’s bepalen | URL’s rangschikken op belang en relevantie |
| Herhaling | Cyclus voortzetten | Volgende URL uit de wachtrij verwerken |
Voordat een crawler een nieuwe URL op een domein bezoekt, controleren verantwoordelijke crawlers het robots.txt-bestand dat zich in de hoofdmap van dat domein bevindt. Dit bestand bevat instructies waarmee website-eigenaren aan crawlers kunnen aangeven welke pagina’s gecrawld mogen worden en welke niet. Bijvoorbeeld, een website-eigenaar kan robots.txt gebruiken om crawlers te verhinderen gevoelige pagina’s, dubbele content of zware secties die de server kunnen overbelasten, te bezoeken. De meeste legitieme zoekmachinecrawlers respecteren deze instructies om goede relaties met website-eigenaren te onderhouden en prestatieproblemen te voorkomen.
Stel geavanceerde tracking in binnen enkele minuten. Geen creditcard vereist.
Moderne webcrawlers zijn aanzienlijk geëvolueerd om de complexiteit van hedendaagse websites aan te kunnen. Veel websites gebruiken tegenwoordig JavaScript om content dynamisch te genereren nadat de pagina is geladen, waardoor de initiële HTML-respons niet alle paginainhoud bevat. Geavanceerde crawlers gebruiken nu headless browsers om JavaScript uit te voeren en dynamisch geladen content vast te leggen die voor traditionele crawlers niet zichtbaar zou zijn. Deze mogelijkheid is essentieel voor het crawlen van single-page applicaties, interactieve dashboards en moderne webapplicaties die sterk afhankelijk zijn van client-side rendering.
Crawlers implementeren geavanceerde prioriteringsalgoritmen om efficiënt om te gaan met hun crawlbudget—het beperkte aantal pagina’s dat ze binnen een bepaalde tijdspanne kunnen crawlen. Deze algoritmen houden rekening met meerdere factoren, waaronder paginawaarde (bepaald door de kwaliteit en kwantiteit van backlinks), interne linkstructuur, actualiteit van de content, bezoekersvolume en domeinreputatie. Pagina’s met een hoge autoriteit en vaak bijgewerkte content krijgen vaker een crawlbezoek, terwijl minder belangrijke of statische pagina’s minder vaak of helemaal niet worden bezocht. Deze intelligente prioritering zorgt ervoor dat crawlers hun middelen richten op de meest waardevolle en veranderlijke content.
Crawldelay en snelheidsbeperking zijn belangrijke mechanismen om te voorkomen dat crawlers webservers overbelasten. Verantwoordelijke crawlers nemen pauzes tussen verzoeken en respecteren de crawldelay-instellingen die zijn opgegeven in robots.txt-bestanden. Dit beleefde crawlgedrag beschermt de prestaties van de website en de gebruikerservaring door ervoor te zorgen dat crawlerverkeer niet buitensporig veel serverbronnen verbruikt. Websites die traag laden of fouten retourneren, kunnen een lagere crawlfrequentie ervaren omdat crawlers automatisch vertragen om problemen te voorkomen.
Verschillende typen webcrawlers dienen uiteenlopende doelen in het digitale ecosysteem. Algemene webcrawlers worden door grote zoekmachines ingezet om zonder onderscheid het hele internet te crawlen en zo uitgebreide indexen op te bouwen voor zoekresultaten. Deze crawlers zijn ontworpen voor maximale dekking en werken continu om nieuwe content te ontdekken en bestaande indexen bij te werken. Verticale of gespecialiseerde crawlers richten zich op specifieke sectoren of contenttypes, zoals jobcrawlers die vacaturesites doorzoeken, prijsvergelijkingscrawlers die prijsdata van webshops verzamelen, of onderzoeksbots die academische artikelen en wetenschappelijke publicaties indexeren.
Incrementele crawlers zijn gericht op efficiëntie door alleen nieuwe of recent gewijzigde content te crawlen, in plaats van steeds hele websites te herhalen. Deze aanpak vermindert de serverbelasting en het bandbreedteverbruik aanzienlijk, terwijl de indexen relatief actueel blijven. Gefocuste crawlers gebruiken geavanceerde algoritmen om te zoeken naar content over specifieke onderwerpen of zoekwoorden, en prioriteren intelligent de pagina’s die waarschijnlijk relevante informatie bevatten. Realtime crawlers monitoren websites continu en werken hun verzamelde data real-time of bijna real-time bij, waardoor ze ideaal zijn voor nieuwsaggregatie- en social media-monitoringtoepassingen.
Parallelle crawlers en gedistribueerde crawlers vormen het infrastructuurintensieve einde van het crawlerspectrum. Parallelle crawlers draaien op meerdere machines of threads tegelijk om de crawlsnelheid en verwerkingscapaciteit drastisch te verhogen. Gedistribueerde crawlers verdelen het werk over meerdere servers of datacenters, waardoor ze enorme hoeveelheden data efficiënt kunnen verwerken. Grote zoekmachines zoals Google gebruiken gedistribueerde crawlerarchitecturen om de miljarden pagina’s op het internet aan te kunnen.
Wees de eerste die op de hoogte is van nieuwe functies en productupdates.
Webcrawlers spelen een fundamentele rol in zoekmachine-optimalisatie omdat zij bepalen welke pagina’s worden geïndexeerd en hoe zoekmachines je content begrijpen. Als crawlers je pagina’s niet kunnen bereiken, verschijnen deze niet in zoekresultaten—ongeacht hun kwaliteit of relevantie. Veelvoorkomende crawlproblemen die de indexering verhinderen zijn pagina’s die worden geblokkeerd door robots.txt, gebroken interne links die leiden tot 404-fouten, trage laadtijden waardoor crawlers afhaken en JavaScript-problemen waardoor crawlers dynamisch gegenereerde content niet kunnen zien.
Website-eigenaren kunnen crawler-toegang optimaliseren met enkele belangrijke strategieën. Een duidelijke sitestructuur met logische navigatiehiërarchieën helpt crawlers de relaties en het belang van pagina’s te begrijpen. Interne linkbuilding geeft crawlers signalen over welke pagina’s het belangrijkst zijn en helpt het crawlbudget efficiënt over de site te verdelen. XML-sitemaps geven expliciet alle belangrijke pagina’s op, zodat crawlers geen content missen, zelfs niet op grote of complexe websites. Snelle laadtijden moedigen crawlers aan om meer pagina’s binnen het beschikbare crawlbudget te bezoeken, terwijl regelmatig bijgewerkte content aangeeft dat een site vaker gecrawld verdient te worden.
Voor affiliate marketeers die platforms zoals PostAffiliatePro gebruiken, is een goede crawler-toegang essentieel om organisch verkeer naar affiliate content te sturen. Wanneer je affiliate productpagina’s, vergelijkingsartikelen en promotiemateriaal goed gecrawld en geïndexeerd worden, krijgen ze de kans om hoog te ranken in zoekresultaten en gekwalificeerd verkeer aan te trekken. Slechte crawlbaarheid kan leiden tot gemiste indexeerkansen en verminderde zichtbaarheid van je affiliate-aanbiedingen.
Website-eigenaren hebben verschillende mechanismen om te bepalen hoe crawlers met hun sites omgaan. Het robots.txt-bestand is het belangrijkste hulpmiddel en bevat instructies die aangeven welke user-agents (soorten crawlers) toegang hebben tot welke gedeelten van de website. Een goed geconfigureerd robots.txt-bestand voorkomt dat crawlers middelen verspillen aan dubbele content, testomgevingen of zware pagina’s, terwijl ze belangrijke content vrij kunnen crawlen. De robots meta-tag staat in de HTML van individuele pagina’s en biedt controle op paginaniveau, zodat specifieke pagina’s kunnen worden uitgesloten van indexering of hun links kunnen worden genegeerd.
Het nofollow-linkattribuut geeft aan dat crawlers een bepaalde hyperlink niet moeten volgen, wat handig is om te voorkomen dat crawlers links naar onbetrouwbare externe sites of door gebruikers gegenereerde content volgen. Deze controlemiddelen werken samen om website-eigenaren gedetailleerde controle te geven over het gedrag van crawlers, terwijl ze goede relaties met zoekmachines behouden. Het is echter belangrijk te beseffen dat kwaadwillende webscrapers en agressieve bots deze instructies vaak negeren, waardoor aanvullende beveiligingsmaatregelen zoals snelheidsbeperking en botdetectie soms noodzakelijk zijn.
Voor affiliate netwerkbeheerders en marketeers heeft inzicht in het gedrag van webcrawlers directe invloed op zakelijk succes. Crawlers bepalen de zichtbaarheid van affiliate productpagina’s, vergelijkingscontent en promotiemateriaal in zoekresultaten. Wanneer gebruikers van PostAffiliatePro hun affiliate websites optimaliseren voor goede crawling, vergroten ze de kans dat hun content door zoekmachines wordt ontdekt en gerankt op relevante zoekwoorden. Deze organische zichtbaarheid zorgt voor gekwalificeerd verkeer naar affiliate-aanbiedingen, wat de conversiekans en commissie-inkomsten vergroot.
Affiliate netwerken profiteren op meerdere manieren van crawleractiviteit. Zoekmachinecrawlers helpen affiliate content over het internet te verspreiden, wat de naamsbekendheid en het bereik vergroot. Crawlers maken het ook mogelijk dat prijsvergelijkingssites en contentaggregators affiliate producten ontdekken en tonen, wat extra verkeersbronnen creëert. Affiliate marketeers moeten echter ook alert zijn op kwaadwillende crawlers en scrapers die affiliate content kunnen kopiëren of zich schuldig maken aan klikfraude. Het implementeren van goede snelheidsbeperking, botdetectie en contentbescherming helpt de integriteit van het affiliate netwerk te waarborgen, terwijl legitieme crawlers hun werk kunnen blijven doen.
PostAffiliatePro biedt uitgebreide tracking- en rapportagemogelijkheden die een goede crawleroptimalisatie aanvullen. Door te zorgen dat je affiliate content correct wordt gecrawld en geïndexeerd, in combinatie met de geavanceerde tracking en analyses van PostAffiliatePro, maximaliseer je de zichtbaarheid en winstgevendheid van je affiliate netwerk. De real-time commissietracking en intelligente rapportages van het platform helpen je te begrijpen welke affiliate kanalen het meest waardevolle verkeer opleveren, zodat je je netwerkstrategie hierop kunt afstemmen.
Net zoals webcrawlers systematisch content ontdekken en indexeren, volgt en optimaliseert PostAffiliatePro systematisch je affiliate-relaties. Ons platform biedt real-time tracking, uitgebreide rapportages en intelligent commissiebeheer om je te helpen een bloeiend affiliate-netwerk op te bouwen.
Crawlers verzamelen data en informatie van het internet door websites te bezoeken en pagina's te lezen. Ontdek meer over hun werking.
Leer wat de Google Spider (Googlebot) is, hoe deze websites crawlt en indexeert, en waarom dit essentieel is voor SEO. Ontdek hoe je jouw site kunt optimalisere...
Spiders zijn bots die worden ingezet voor spamdoeleinden en kunnen grote problemen veroorzaken voor je bedrijf. Lees meer over ze in het artikel.
Sluit u aan bij onze gemeenschap van tevreden klanten en bied uitstekende klantenservice met Post Affiliate Pro.